 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Curse of Quality Saturation with User-Centric Ranking
Paper and Code
May 24, 2023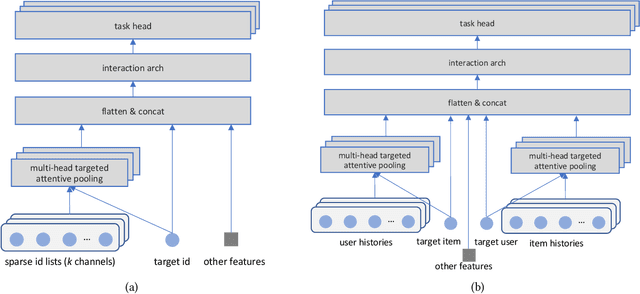

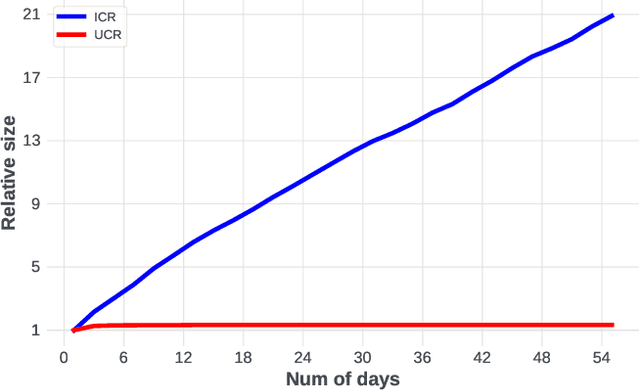
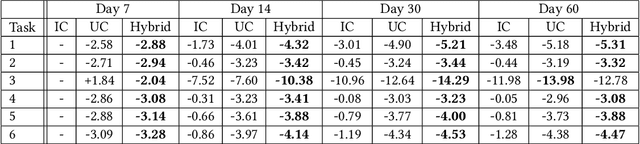
A key puzzle in search, ads, and recommendation is that the ranking model can only utilize a small portion of the vastly available user interaction data. As a result, increasing data volume, model size, or computation FLOPs will quickly suffer from diminishing returns. We examined this problem and found that one of the root causes may lie in the so-called ``item-centric'' formulation, which has an unbounded vocabulary and thus uncontrolled model complexity. To mitigate quality saturation, we introduce an alternative formulation named ``user-centric ranking'', which is based on a transposed view of the dyadic user-item interaction data. We show that this formulation has a promising scaling property, enabling us to train better-converged models on substantially larger data sets.