 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Monocular Depth Estimation with Sparse Guided Points
Paper and Code
Feb 03, 2022
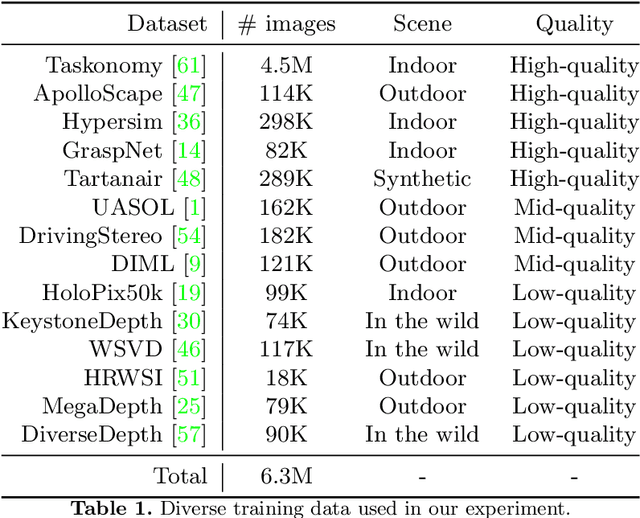

Existing monocular depth estimation shows excellent robustness in the wild, but the affine-invariant prediction requires aligning with the ground truth globally while being converted into the metric depth. In this work, we firstly propose a modified locally weighted linear regression strategy to leverage sparse ground truth and generate a flexible depth transformation to correct the coarse misalignment brought by global recovery strategy. Applying this strategy, we achieve significant improvement (more than 50% at most) over most recent state-of-the-art methods on five zero-shot datasets. Moreover, we train a robust depth estimation model with 6.3 million data and analyze the training process by decoupling the inaccuracy into coarse misalignment inaccuracy and detail missing inaccuracy. As a result, our model based on ResNet50 even outperforms the state-of-the-art DPT ViT-Large model with the help of our recovery strategy. In addition to accuracy, the consistency is also boosted for simple per-frame video depth estimation. Compared with monocular depth estimation, robust video depth estimation, and depth completion methods, our pipeline obtains state-of-the-art performance on video depth estimation without any post-processing. Experiments of 3D scene reconstruction from consistent video depth are conducted for intuitive comparison as well.