 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBGM: Building a Dynamic Guidance Map without Visual Images for Trajectory Prediction
Paper and Code
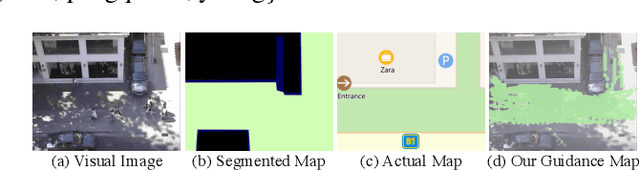
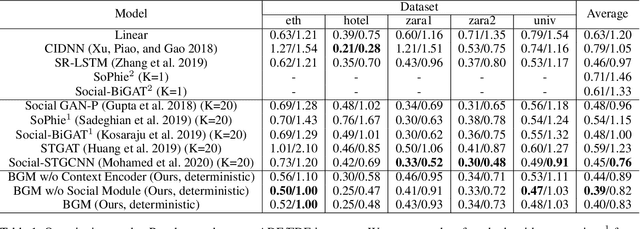
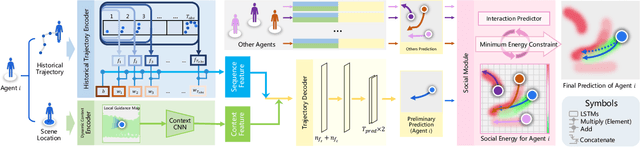
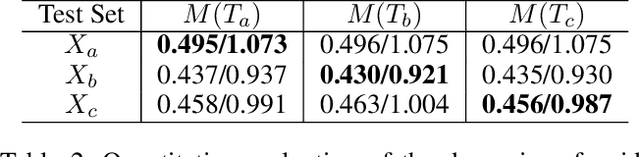
Visual images usually contain the informative context of the environment, thereby helping to predict agents' behaviors. However, they hardly impose the dynamic effects on agents' actual behaviors due to the respectively fixed semantics. To solve this problem, we propose a deterministic model named BGM to construct a guidance map to represent the dynamic semantics, which circumvents to use visual images for each agent to reflect the difference of activities in different periods. We first record all agents' activities in the scene within a period close to the current to construct a guidance map and then feed it to a Context CNN to obtain their context features. We adopt a Historical Trajectory Encoder to extract the trajectory features and then combine them with the context feature as the input of the social energy based trajectory decoder, thus obtaining the prediction that meets the social rules. Experiments demonstrate that BGM achieves state-of-the-art prediction accuracy on the two widely used ETH and UCY datasets and handles more complex scenarios.