 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
Paper and Code


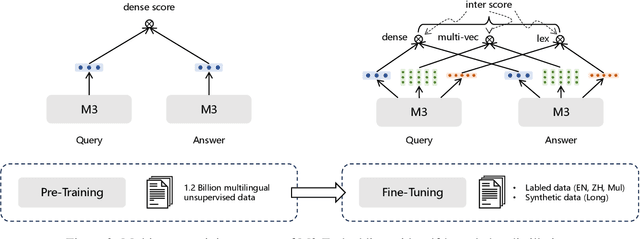

In this paper, we present a new embedding model, called M3-Embedding, which is distinguished for its versatility in Multi-Linguality, Multi-Functionality, and Multi-Granularity. It can support more than 100 working languages, leading to new state-of-the-art performances on multi-lingual and cross-lingual retrieval tasks. It can simultaneously perform the three common retrieval functionalities of embedding model: dense retrieval, multi-vector retrieval, and sparse retrieval, which provides a unified model foundation for real-world IR applications. It is able to process inputs of different granularities, spanning from short sentences to long documents of up to 8192 tokens. The effective training of M3-Embedding involves the following technical contributions. We propose a novel self-knowledge distillation approach, where the relevance scores from different retrieval functionalities can be integrated as the teacher signal to enhance the training quality. We also optimize the batching strategy, enabling a large batch size and high training throughput to ensure the discriminativeness of embeddings. To the best of our knowledge, M3-Embedding is the first embedding model which realizes such a strong versatility. The model and code will be publicly available at https://github.com/FlagOpen/FlagEmbedding.