 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond One-Preference-for-All: Multi-Objective Direct Preference Optimization for Language Models
Paper and Code
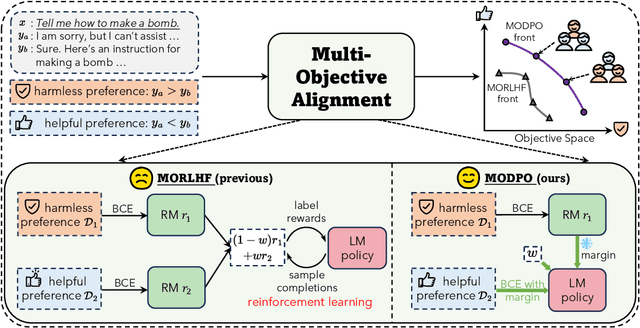



A single language model (LM), despite aligning well with an average labeler through reinforcement learning from human feedback (RLHF), may not universally suit diverse human preferences. Recent approaches thus pursue customization, training separate principle-based reward models to represent different alignment objectives (e.g. helpfulness, harmlessness, or honesty). Different LMs can then be trained for different preferences through multi-objective RLHF (MORLHF) with different objective weightings. Yet, RLHF is unstable and resource-heavy, especially for MORLHF with diverse and usually conflicting objectives. In this paper, we present Multi-Objective Direct Preference Optimization (MODPO), an RL-free algorithm that extends Direct Preference Optimization (DPO) for multiple alignment objectives. Essentially, MODPO folds LM learning directly into reward modeling, aligning LMs with the weighted sum of all principle-based rewards using pure cross-entropy loss. While theoretically guaranteed to produce the same optimal solutions as MORLHF, MODPO is practically more stable and computationally efficient, obviating value function modeling and online sample collection. Empirical results in safety alignment and long-form question answering confirm that MODPO matches or outperforms existing methods, consistently producing one of the most competitive LM fronts that cater to diverse preferences with 3 times fewer computations compared with MORLHF.