 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Resource Usage for Efficient Distributed Deep Learning
Paper and Code
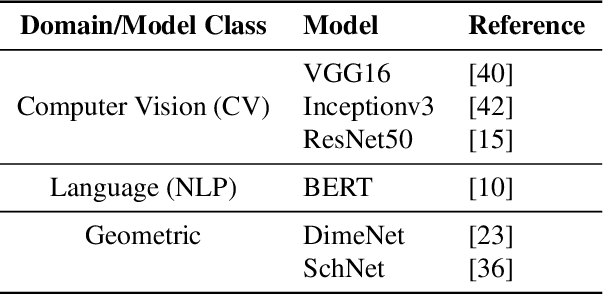
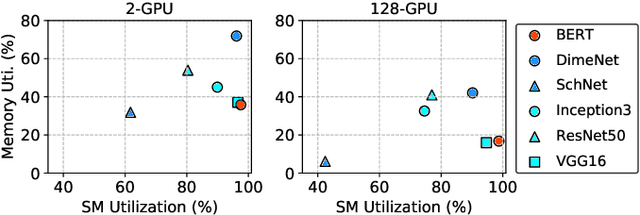

Deep learning (DL) workflows demand an ever-increasing budget of compute and energy in order to achieve outsized gains. Neural architecture searches, hyperparameter sweeps, and rapid prototyping consume immense resources that can prevent resource-constrained researchers from experimenting with large models and carry considerable environmental impact. As such, it becomes essential to understand how different deep neural networks (DNNs) and training leverage increasing compute and energy resources -- especially specialized computationally-intensive models across different domains and applications. In this paper, we conduct over 3,400 experiments training an array of deep networks representing various domains/tasks -- natural language processing, computer vision, and chemistry -- on up to 424 graphics processing units (GPUs). During training, our experiments systematically vary compute resource characteristics and energy-saving mechanisms such as power utilization and GPU clock rate limits to capture and illustrate the different trade-offs and scaling behaviors each representative model exhibits under various resource and energy-constrained regimes. We fit power law models that describe how training time scales with available compute resources and energy constraints. We anticipate that these findings will help inform and guide high-performance computing providers in optimizing resource utilization, by selectively reducing energy consumption for different deep learning tasks/workflows with minimal impact on training.