 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmentations in Graph Contrastive Learning: Current Methodological Flaws & Towards Better Practices
Paper and Code
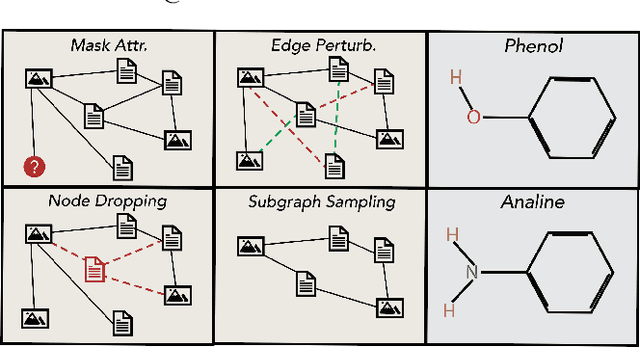



Graph classification has applications in bioinformatics, social sciences, automated fake news detection, web document classification, and more. In many practical scenarios, including web-scale applications, where labels are scarce or hard to obtain, unsupervised learning is a natural paradigm but it trades off performance. Recently, contrastive learning (CL) has enabled unsupervised computer vision models to compete well against supervised ones. Theoretical and empirical works analyzing visual CL frameworks find that leveraging large datasets and domain aware augmentations is essential for framework success. Interestingly, graph CL frameworks often report high performance while using orders of magnitude smaller data, and employing domain-agnostic augmentations (e.g., node or edge dropping, feature perturbations) that can corrupt the graphs' underlying properties. Motivated by these discrepancies, we seek to determine: (i) why existing graph CL frameworks perform well despite weak augmentations and limited data; and (ii) whether adhering to visual CL principles can improve performance on graph classification tasks. Through extensive analysis, we identify flawed practices in graph data augmentation and evaluation protocols that are commonly used in the graph CL literature, and propose improved practices and sanity checks for future research and applications. We show that on small benchmark datasets, the inductive bias of graph neural networks can significantly compensate for the limitations of existing frameworks. In case studies with relatively larger graph classification tasks, we find that commonly used domain-agnostic augmentations perform poorly, while adhering to principles in visual CL can significantly improve performance. For example, in graph-based document classification, which can be used for better web search, we show task-relevant augmentations improve accuracy by 20%.