 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomas: Hierarchical Alignment on Molecule-Text for Unified Molecule Understanding and Generation
Paper and Code
Apr 23, 2024

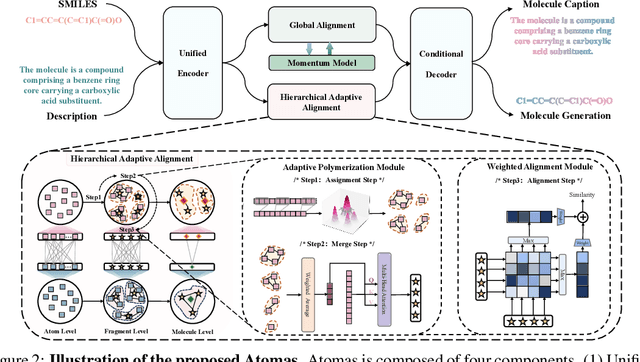

Molecule-and-text cross-modal representation learning has emerged as a promising direction for enhancing the quality of molecular representation, thereby improving performance in various scientific fields, including drug discovery and materials science. Existing studies adopt a global alignment approach to learn the knowledge from different modalities. These global alignment approaches fail to capture fine-grained information, such as molecular fragments and their corresponding textual description, which is crucial for downstream tasks. Furthermore, it is incapable to model such information using a similar global alignment strategy due to data scarcity of paired local part annotated data from existing datasets. In this paper, we propose Atomas, a multi-modal molecular representation learning framework to jointly learn representations from SMILES string and text. We design a Hierarchical Adaptive Alignment model to concurrently learn the fine-grained fragment correspondence between two modalities and align these representations of fragments in three levels. Additionally, Atomas's end-to-end training framework incorporates the tasks of understanding and generating molecule, thereby supporting a wider range of downstream tasks. In the retrieval task, Atomas exhibits robust generalization ability and outperforms the baseline by 30.8% of recall@1 on average. In the generation task, Atomas achieves state-of-the-art results in both molecule captioning task and molecule generation task. Moreover, the visualization of the Hierarchical Adaptive Alignment model further confirms the chemical significance of our approach. Our codes can be found at https://anonymous.4open.science/r/Atomas-03C3.