 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymptotic behavior of $\ell_p$-based Laplacian regularization in semi-supervised learning
Paper and Code
Mar 02, 2016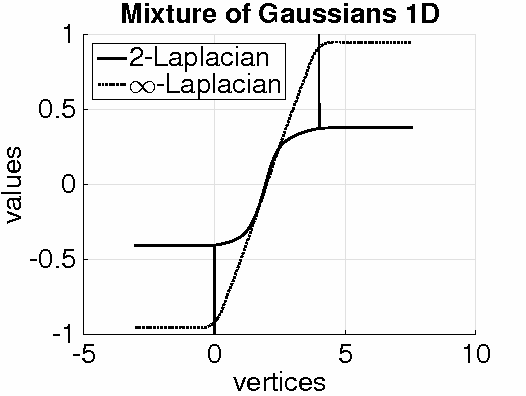
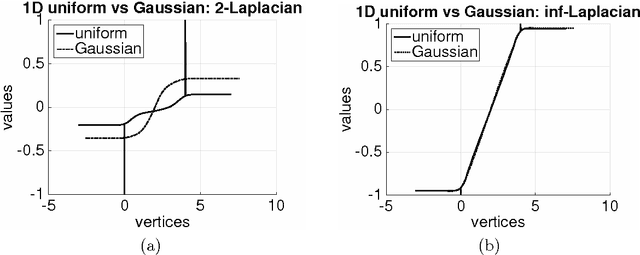
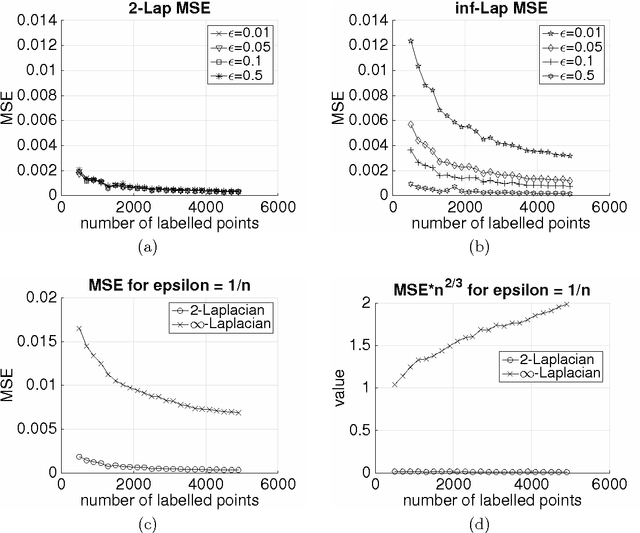
Given a weighted graph with $N$ vertices, consider a real-valued regression problem in a semi-supervised setting, where one observes $n$ labeled vertices, and the task is to label the remaining ones. We present a theoretical study of $\ell_p$-based Laplacian regularization under a $d$-dimensional geometric random graph model. We provide a variational characterization of the performance of this regularized learner as $N$ grows to infinity while $n$ stays constant, the associated optimality conditions lead to a partial differential equation that must be satisfied by the associated function estimate $\hat{f}$. From this formulation we derive several predictions on the limiting behavior the $d$-dimensional function $\hat{f}$, including (a) a phase transition in its smoothness at the threshold $p = d + 1$, and (b) a tradeoff between smoothness and sensitivity to the underlying unlabeled data distribution $P$. Thus, over the range $p \leq d$, the function estimate $\hat{f}$ is degenerate and "spiky," whereas for $p\geq d+1$, the function estimate $\hat{f}$ is smooth. We show that the effect of the underlying density vanishes monotonically with $p$, such that in the limit $p = \infty$, corresponding to the so-called Absolutely Minimal Lipschitz Extension, the estimate $\hat{f}$ is independent of the distribution $P$. Under the assumption of semi-supervised smoothness, ignoring $P$ can lead to poor statistical performance, in particular, we construct a specific example for $d=1$ to demonstrate that $p=2$ has lower risk than $p=\infty$ due to the former penalty adapting to $P$ and the latter ignoring it. We also provide simulations that verify the accuracy of our predictions for finite sample sizes. Together, these properties show that $p = d+1$ is an optimal choice, yielding a function estimate $\hat{f}$ that is both smooth and non-degenerate, while remaining maximally sensitive to $P$.