Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsking Easy Questions: A User-Friendly Approach to Active Reward Learning
Paper and Code



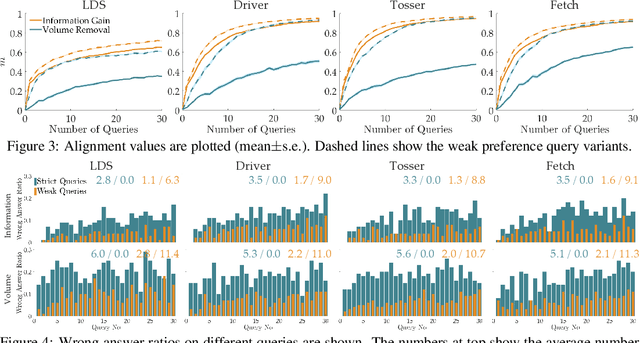
Robots can learn the right reward function by querying a human expert. Existing approaches attempt to choose questions where the robot is most uncertain about the human's response; however, they do not consider how easy it will be for the human to answer! In this paper we explore an information gain formulation for optimally selecting questions that naturally account for the human's ability to answer. Our approach identifies questions that optimize the trade-off between robot and human uncertainty, and determines when these questions become redundant or costly. Simulations and a user study show our method not only produces easy questions, but also ultimately results in faster reward learning.
* Proceedings of the 3rd Conference on Robot Learning (CoRL), October
2019
View paper on