 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJudgeLRM: Large Reasoning Models as a Judge
Paper and Code
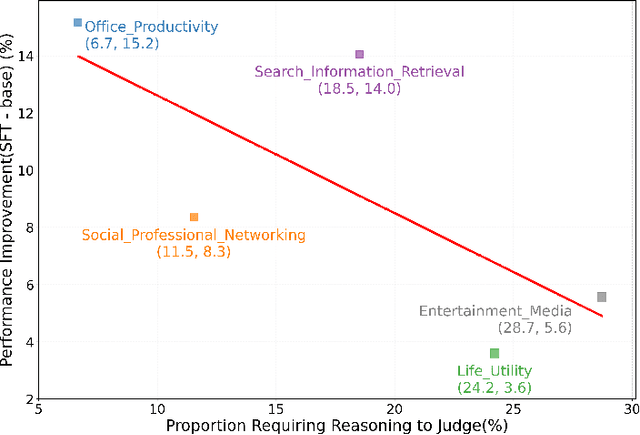
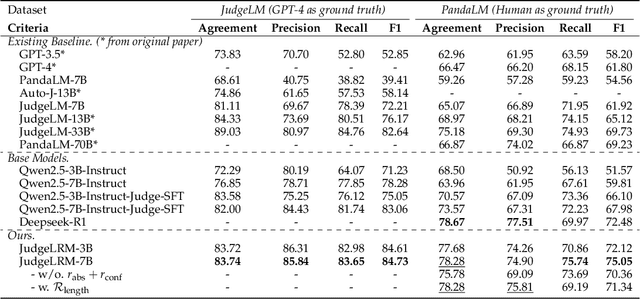


The rise of Large Language Models (LLMs) as evaluators offers a scalable alternative to human annotation, yet existing Supervised Fine-Tuning (SFT) for judges approaches often fall short in domains requiring complex reasoning. In this work, we investigate whether LLM judges truly benefit from enhanced reasoning capabilities. Through a detailed analysis of reasoning requirements across evaluation tasks, we reveal a negative correlation between SFT performance gains and the proportion of reasoning-demanding samples - highlighting the limitations of SFT in such scenarios. To address this, we introduce JudgeLRM, a family of judgment-oriented LLMs trained using reinforcement learning (RL) with judge-wise, outcome-driven rewards. JudgeLRM models consistently outperform both SFT-tuned and state-of-the-art reasoning models. Notably, JudgeLRM-3B surpasses GPT-4, and JudgeLRM-7B outperforms DeepSeek-R1 by 2.79% in F1 score, particularly excelling in judge tasks requiring deep reasoning.