 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlternating Optimisation and Quadrature for Robust Control
Paper and Code
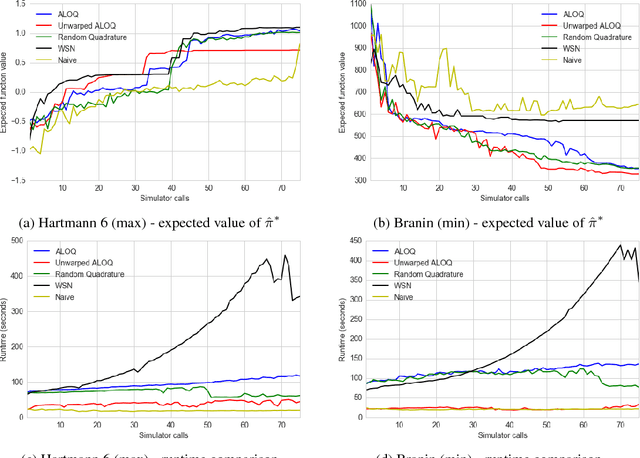
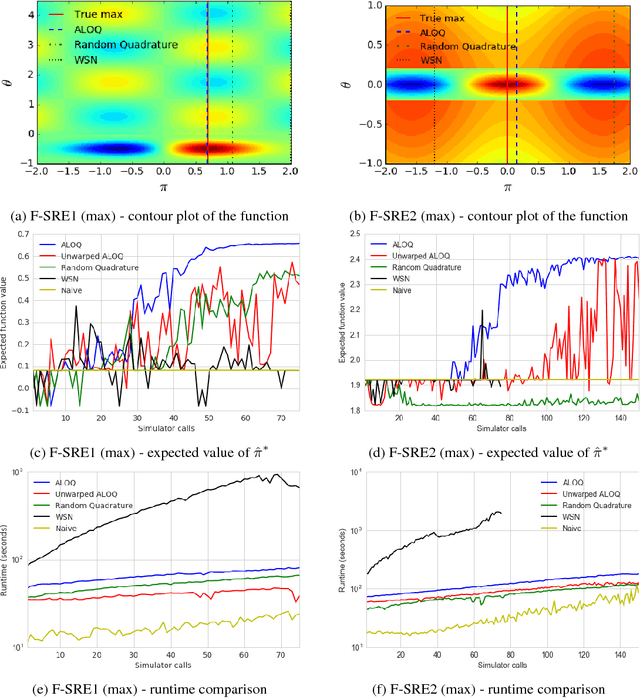

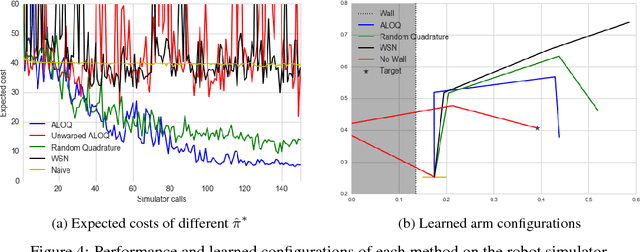
Bayesian optimisation has been successfully applied to a variety of reinforcement learning problems. However, the traditional approach for learning optimal policies in simulators does not utilise the opportunity to improve learning by adjusting certain environment variables: state features that are unobservable and randomly determined by the environment in a physical setting but are controllable in a simulator. This paper considers the problem of finding a robust policy while taking into account the impact of environment variables. We present Alternating Optimisation and Quadrature (ALOQ), which uses Bayesian optimisation and Bayesian quadrature to address such settings. ALOQ is robust to the presence of significant rare events, which may not be observable under random sampling, but play a substantial role in determining the optimal policy. Experimental results across different domains show that ALOQ can learn more efficiently and robustly than existing methods.