 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEI: Actors-Environment Interaction with Adaptive Attention for Temporal Action Proposals Generation
Paper and Code
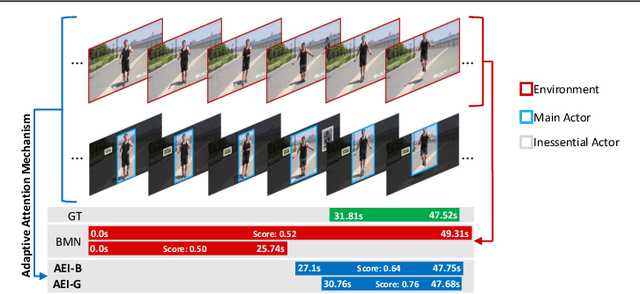
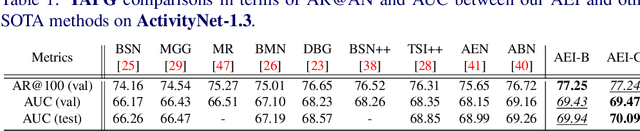

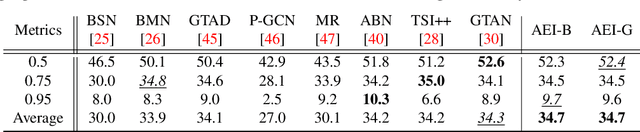
Humans typically perceive the establishment of an action in a video through the interaction between an actor and the surrounding environment. An action only starts when the main actor in the video begins to interact with the environment, while it ends when the main actor stops the interaction. Despite the great progress in temporal action proposal generation, most existing works ignore the aforementioned fact and leave their model learning to propose actions as a black-box. In this paper, we make an attempt to simulate that ability of a human by proposing Actor Environment Interaction (AEI) network to improve the video representation for temporal action proposals generation. AEI contains two modules, i.e., perception-based visual representation (PVR) and boundary-matching module (BMM). PVR represents each video snippet by taking human-human relations and humans-environment relations into consideration using the proposed adaptive attention mechanism. Then, the video representation is taken by BMM to generate action proposals. AEI is comprehensively evaluated in ActivityNet-1.3 and THUMOS-14 datasets, on temporal action proposal and detection tasks, with two boundary-matching architectures (i.e., CNN-based and GCN-based) and two classifiers (i.e., Unet and P-GCN). Our AEI robustly outperforms the state-of-the-art methods with remarkable performance and generalization for both temporal action proposal generation and temporal action detection.