 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing High-Resolution Video-Language Representation with Large-Scale Video Transcriptions
Paper and Code
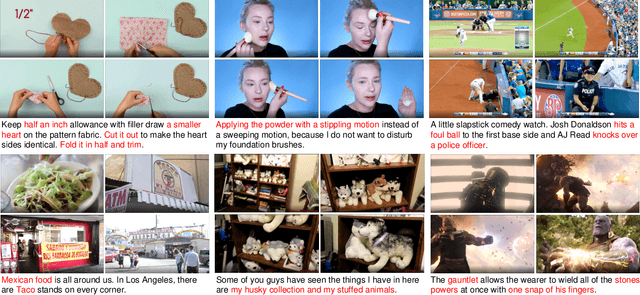
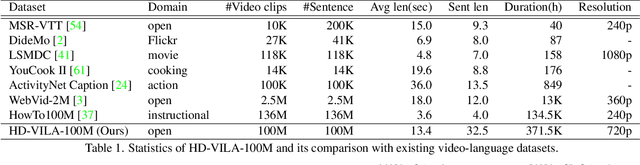
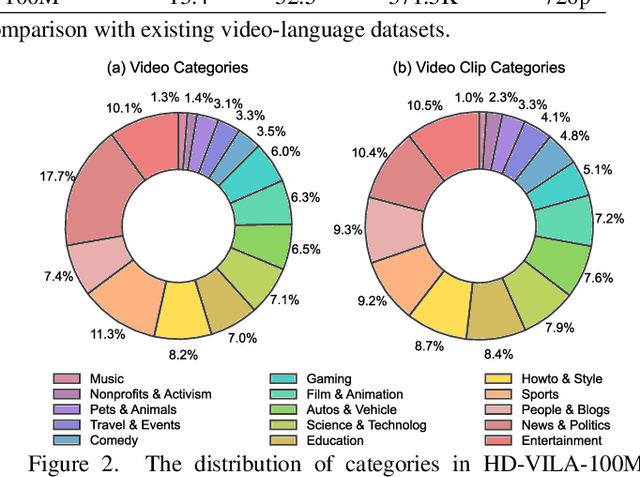

We study joint video and language (VL) pre-training to enable cross-modality learning and benefit plentiful downstream VL tasks. Existing works either extract low-quality video features or learn limited text embedding, while neglecting that high-resolution videos and diversified semantics can significantly improve cross-modality learning. In this paper, we propose a novel High-resolution and Diversified VIdeo-LAnguage pre-training model (HD-VILA) for many visual tasks. In particular, we collect a large dataset with two distinct properties: 1) the first high-resolution dataset including 371.5k hours of 720p videos, and 2) the most diversified dataset covering 15 popular YouTube categories. To enable VL pre-training, we jointly optimize the HD-VILA model by a hybrid Transformer that learns rich spatiotemporal features, and a multimodal Transformer that enforces interactions of the learned video features with diversified texts. Our pre-training model achieves new state-of-the-art results in 10 VL understanding tasks and 2 more novel text-to-visual generation tasks. For example, we outperform SOTA models with relative increases of 38.5% R@1 in zero-shot MSR-VTT text-to-video retrieval task, and 53.6% in high-resolution dataset LSMDC. The learned VL embedding is also effective in generating visually pleasing and semantically relevant results in text-to-visual manipulation and super-resolution tasks.