 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing catastrophic forgetting for medical domain expansion
Paper and Code
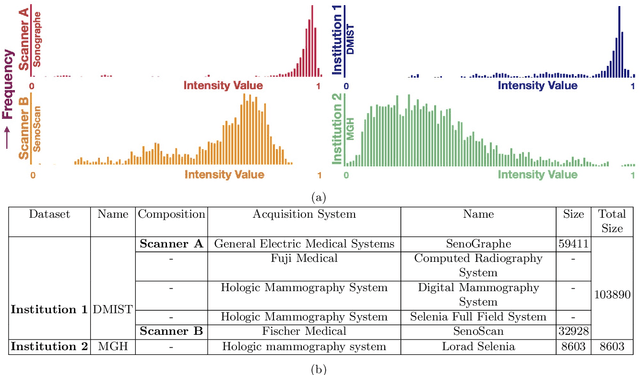
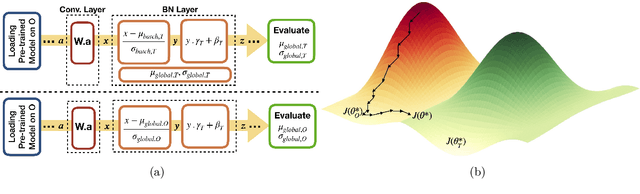
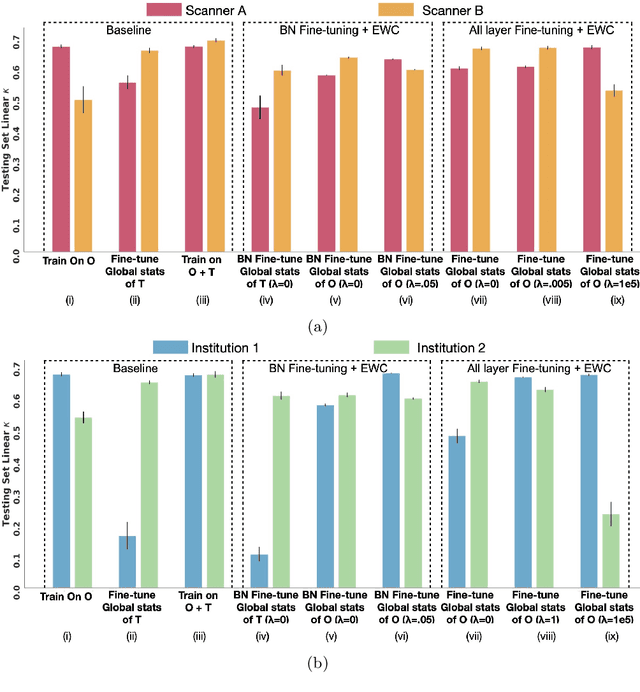
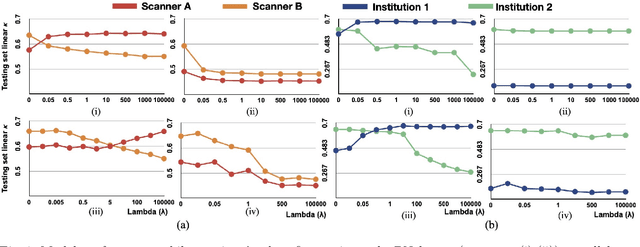
Model brittleness is a key concern when deploying deep learning models in real-world medical settings. A model that has high performance at one institution may suffer a significant decline in performance when tested at other institutions. While pooling datasets from multiple institutions and retraining may provide a straightforward solution, it is often infeasible and may compromise patient privacy. An alternative approach is to fine-tune the model on subsequent institutions after training on the original institution. Notably, this approach degrades model performance at the original institution, a phenomenon known as catastrophic forgetting. In this paper, we develop an approach to address catastrophic forget-ting based on elastic weight consolidation combined with modulation of batch normalization statistics under two scenarios: first, for expanding the domain from one imaging system's data to another imaging system's, and second, for expanding the domain from a large multi-institutional dataset to another single institution dataset. We show that our approach outperforms several other state-of-the-art approaches and provide theoretical justification for the efficacy of batch normalization modulation. The results of this study are generally applicable to the deployment of any clinical deep learning model which requires domain expansion.