 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdding vs. Averaging in Distributed Primal-Dual Optimization
Paper and Code

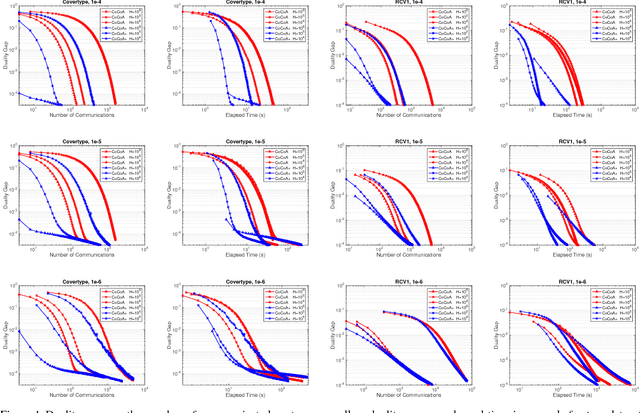
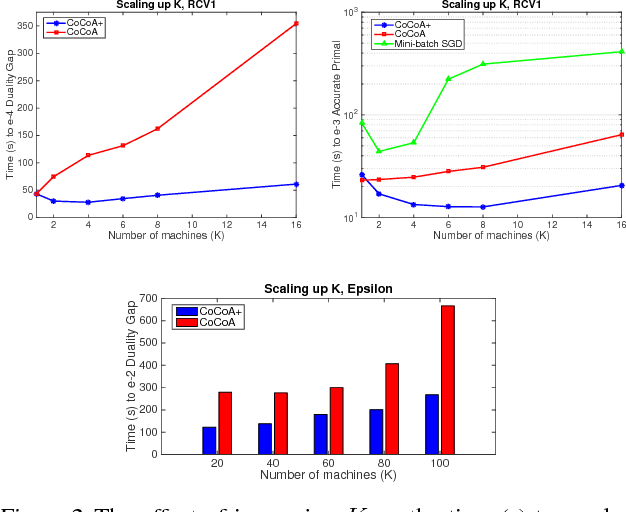
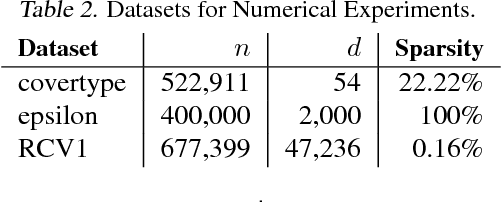
Distributed optimization methods for large-scale machine learning suffer from a communication bottleneck. It is difficult to reduce this bottleneck while still efficiently and accurately aggregating partial work from different machines. In this paper, we present a novel generalization of the recent communication-efficient primal-dual framework (CoCoA) for distributed optimization. Our framework, CoCoA+, allows for additive combination of local updates to the global parameters at each iteration, whereas previous schemes with convergence guarantees only allow conservative averaging. We give stronger (primal-dual) convergence rate guarantees for both CoCoA as well as our new variants, and generalize the theory for both methods to cover non-smooth convex loss functions. We provide an extensive experimental comparison that shows the markedly improved performance of CoCoA+ on several real-world distributed datasets, especially when scaling up the number of machines.