 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdding Conditional Control to Diffusion Models with Reinforcement Learning
Paper and Code
Jun 17, 2024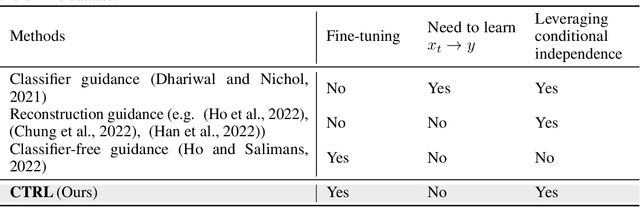
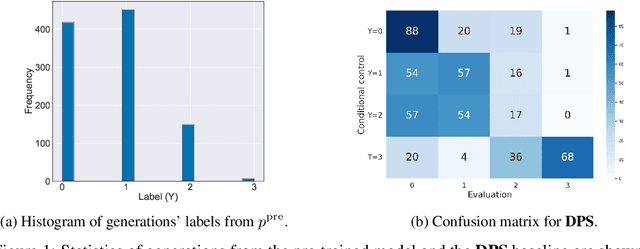
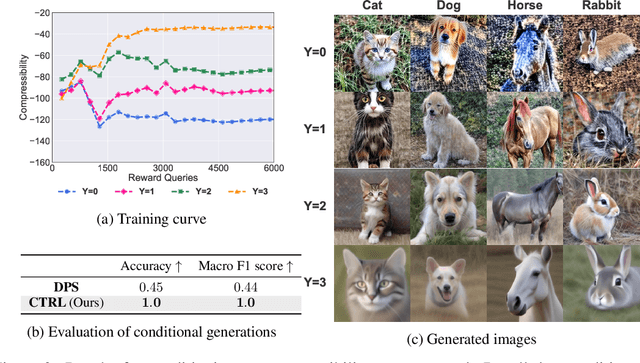
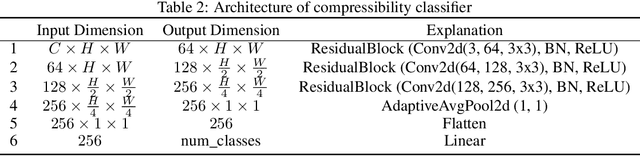
Diffusion models are powerful generative models that allow for precise control over the characteristics of the generated samples. While these diffusion models trained on large datasets have achieved success, there is often a need to introduce additional controls in downstream fine-tuning processes, treating these powerful models as pre-trained diffusion models. This work presents a novel method based on reinforcement learning (RL) to add additional controls, leveraging an offline dataset comprising inputs and corresponding labels. We formulate this task as an RL problem, with the classifier learned from the offline dataset and the KL divergence against pre-trained models serving as the reward functions. We introduce our method, $\textbf{CTRL}$ ($\textbf{C}$onditioning pre-$\textbf{T}$rained diffusion models with $\textbf{R}$einforcement $\textbf{L}$earning), which produces soft-optimal policies that maximize the abovementioned reward functions. We formally demonstrate that our method enables sampling from the conditional distribution conditioned on additional controls during inference. Our RL-based approach offers several advantages over existing methods. Compared to commonly used classifier-free guidance, our approach improves sample efficiency, and can greatly simplify offline dataset construction by exploiting conditional independence between the inputs and additional controls. Furthermore, unlike classifier guidance, we avoid the need to train classifiers from intermediate states to additional controls.