 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionPrompt: Action-Guided 3D Human Pose Estimation With Text and Pose Prompting
Paper and Code
Jul 18, 2023
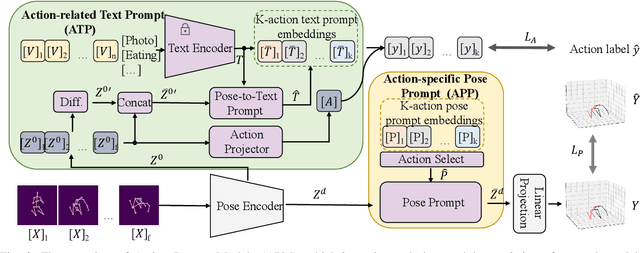
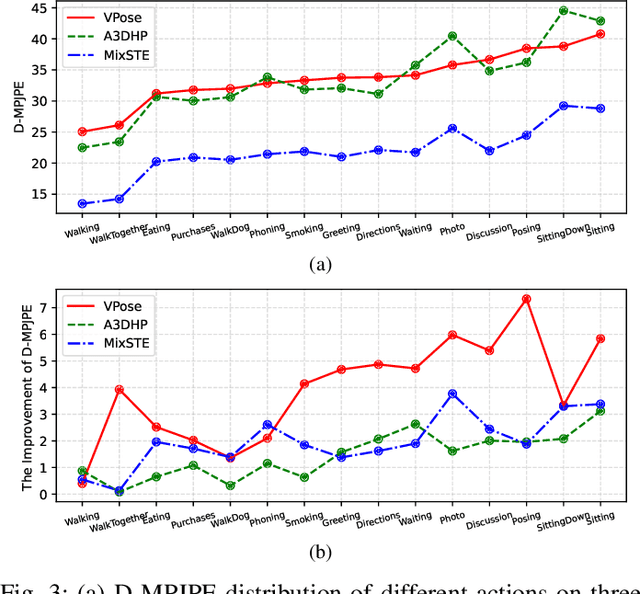
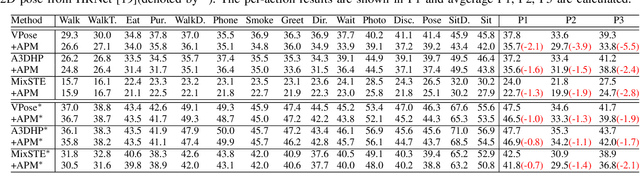
Recent 2D-to-3D human pose estimation (HPE) utilizes temporal consistency across sequences to alleviate the depth ambiguity problem but ignore the action related prior knowledge hidden in the pose sequence. In this paper, we propose a plug-and-play module named Action Prompt Module (APM) that effectively mines different kinds of action clues for 3D HPE. The highlight is that, the mining scheme of APM can be widely adapted to different frameworks and bring consistent benefits. Specifically, we first present a novel Action-related Text Prompt module (ATP) that directly embeds action labels and transfers the rich language information in the label to the pose sequence. Besides, we further introduce Action-specific Pose Prompt module (APP) to mine the position-aware pose pattern of each action, and exploit the correlation between the mined patterns and input pose sequence for further pose refinement. Experiments show that APM can improve the performance of most video-based 2D-to-3D HPE frameworks by a large margin.