 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Single Stage Detector Using Recurrent Rolling Convolution
Paper and Code

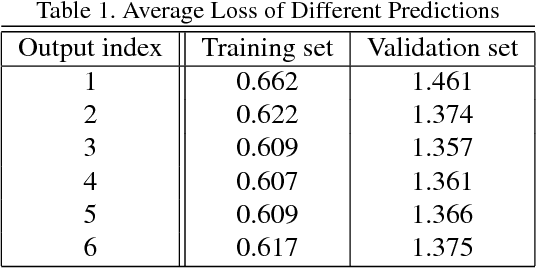

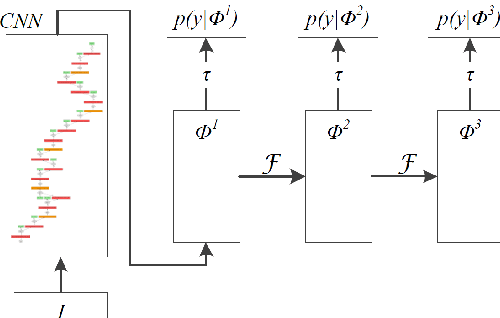
Most of the recent successful methods in accurate object detection and localization used some variants of R-CNN style two stage Convolutional Neural Networks (CNN) where plausible regions were proposed in the first stage then followed by a second stage for decision refinement. Despite the simplicity of training and the efficiency in deployment, the single stage detection methods have not been as competitive when evaluated in benchmarks consider mAP for high IoU thresholds. In this paper, we proposed a novel single stage end-to-end trainable object detection network to overcome this limitation. We achieved this by introducing Recurrent Rolling Convolution (RRC) architecture over multi-scale feature maps to construct object classifiers and bounding box regressors which are "deep in context". We evaluated our method in the challenging KITTI dataset which measures methods under IoU threshold of 0.7. We showed that with RRC, a single reduced VGG-16 based model already significantly outperformed all the previously published results. At the time this paper was written our models ranked the first in KITTI car detection (the hard level), the first in cyclist detection and the second in pedestrian detection. These results were not reached by the previous single stage methods. The code is publicly available.