 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Analyzing and Detecting Malicious Examples of DNN Models
Paper and Code
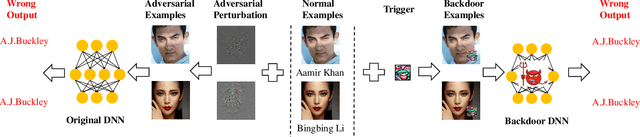

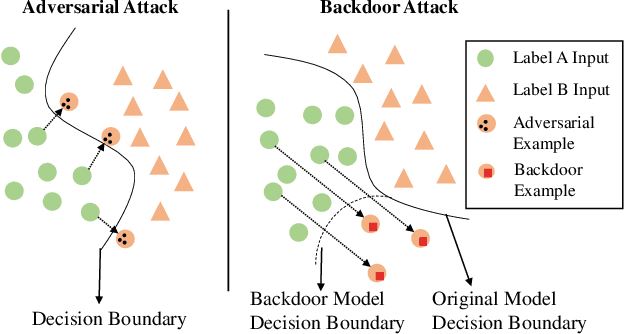
Deep Neural Networks are well known to be vulnerable to adversarial attacks and backdoor attacks, where minor modifications on the input can mislead the models to give wrong results. Although defenses against adversarial attacks have been widely studied, research on mitigating backdoor attacks is still at an early stage. It is unknown whether there are any connections and common characteristics between the defenses against these two attacks. In this paper, we present a unified framework for detecting malicious examples and protecting the inference results of Deep Learning models. This framework is based on our observation that both adversarial examples and backdoor examples have anomalies during the inference process, highly distinguishable from benign samples. As a result, we repurpose and revise four existing adversarial defense methods for detecting backdoor examples. Extensive evaluations indicate these approaches provide reliable protection against backdoor attacks, with a higher accuracy than detecting adversarial examples. These solutions also reveal the relations of adversarial examples, backdoor examples and normal samples in model sensitivity, activation space and feature space. This can enhance our understanding about the inherent features of these two attacks, as well as the defense opportunities.