 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theoretical Understanding of Neural Network Compression from Sparse Linear Approximation
Paper and Code
Jun 11, 2022
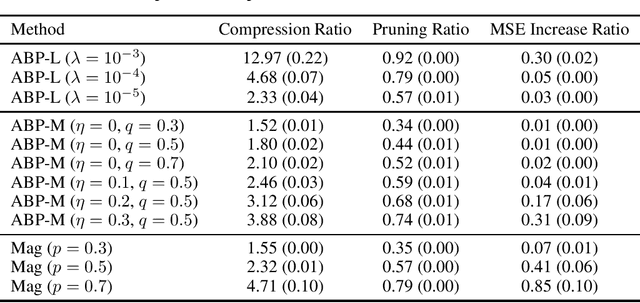
The goal of model compression is to reduce the size of a large neural network while retaining a comparable performance. As a result, computation and memory costs in resource-limited applications may be significantly reduced by dropping redundant weights, neurons, or layers. There have been many model compression algorithms proposed that provide impressive empirical success. However, a theoretical understanding of model compression is still limited. One problem is understanding if a network is more compressible than another of the same structure. Another problem is quantifying how much one can prune a network with theoretically guaranteed accuracy degradation. In this work, we propose to use the sparsity-sensitive $\ell_q$-norm ($0<q<1$) to characterize compressibility and provide a relationship between soft sparsity of the weights in the network and the degree of compression with a controlled accuracy degradation bound. We also develop adaptive algorithms for pruning each neuron in the network informed by our theory. Numerical studies demonstrate the promising performance of the proposed methods compared with standard pruning algorithms.