 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Language Model Confidence Estimation and Calibration
Paper and Code


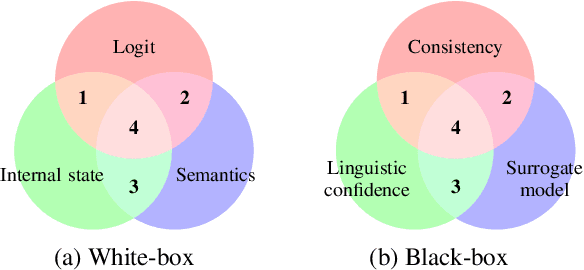
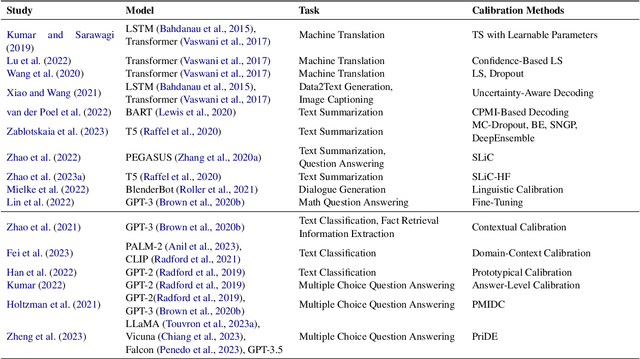
Language models (LMs) have demonstrated remarkable capabilities across a wide range of tasks in various domains. Despite their impressive performance, the reliability of their output is concerning and questionable regarding the demand for AI safety. Assessing the confidence of LM predictions and calibrating them across different tasks with the aim to align LM confidence with accuracy can help mitigate risks and enable LMs to make better decisions. There have been various works in this respect, but there has been no comprehensive overview of this important research area. The present survey aims to bridge this gap. In particular, we discuss methods and techniques for LM confidence estimation and calibration, encompassing different LMs and various tasks. We further outline the challenges of estimating the confidence for large language models and we suggest some promising directions for future work.