 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-facet Paradigm to Bridge Large Language Model and Recommendation
Paper and Code
Oct 10, 2023
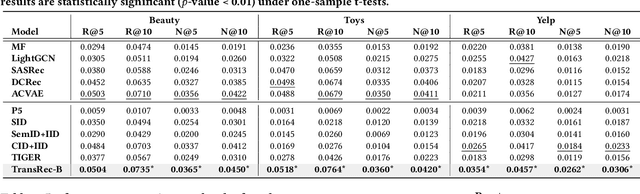


Large Language Models (LLMs) have garnered considerable attention in recommender systems. To achieve LLM-based recommendation, item indexing and generation grounding are two essential steps, bridging between recommendation items and natural language. Item indexing assigns a unique identifier to represent each item in natural language, and generation grounding grounds the generated token sequences to in-corpus items. However, previous works suffer from inherent limitations in the two steps. For item indexing, existing ID-based identifiers (e.g., numeric IDs) and description-based identifiers (e.g., titles) often compromise semantic richness or uniqueness. Moreover, generation grounding might inadvertently produce out-of-corpus identifiers. Worse still, autoregressive generation heavily relies on the initial token's quality. To combat these issues, we propose a novel multi-facet paradigm, namely TransRec, to bridge the LLMs to recommendation. Specifically, TransRec employs multi-facet identifiers that incorporate ID, title, and attribute, achieving both distinctiveness and semantics. Additionally, we introduce a specialized data structure for TransRec to guarantee the in-corpus identifier generation and adopt substring indexing to encourage LLMs to generate from any position. We implement TransRec on two backbone LLMs, i.e., BART-large and LLaMA-7B. Empirical results on three real-world datasets under diverse settings (e.g., full training and few-shot training with warm- and cold-start testings) attest to the superiority of TransRec.