 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Feature Constraint to Camouflage Medical Adversarial Attacks
Paper and Code
Dec 17, 2020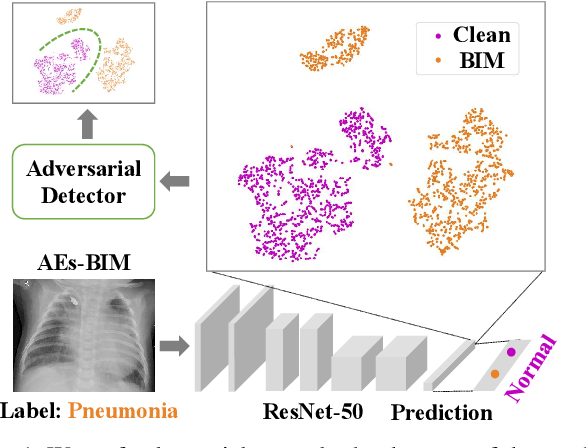
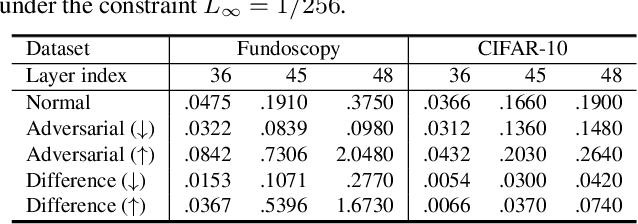
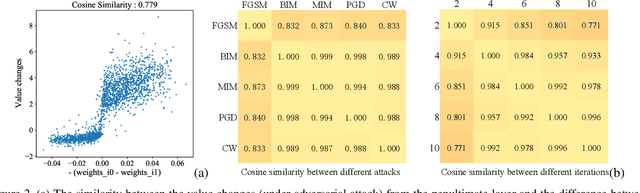
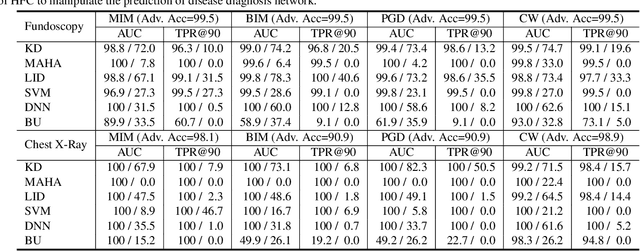
Deep neural networks (DNNs) for medical images are extremely vulnerable to adversarial examples (AEs), which poses security concerns on clinical decision making. Luckily, medical AEs are also easy to detect in hierarchical feature space per our study herein. To better understand this phenomenon, we thoroughly investigate the intrinsic characteristic of medical AEs in feature space, providing both empirical evidence and theoretical explanations for the question: why are medical adversarial attacks easy to detect? We first perform a stress test to reveal the vulnerability of deep representations of medical images, in contrast to natural images. We then theoretically prove that typical adversarial attacks to binary disease diagnosis network manipulate the prediction by continuously optimizing the vulnerable representations in a fixed direction, resulting in outlier features that make medical AEs easy to detect. However, this vulnerability can also be exploited to hide the AEs in the feature space. We propose a novel hierarchical feature constraint (HFC) as an add-on to existing adversarial attacks, which encourages the hiding of the adversarial representation within the normal feature distribution. We evaluate the proposed method on two public medical image datasets, namely {Fundoscopy} and {Chest X-Ray}. Experimental results demonstrate the superiority of our adversarial attack method as it bypasses an array of state-of-the-art adversarial detectors more easily than competing attack methods, supporting that the great vulnerability of medical features allows an attacker more room to manipulate the adversarial representations.