 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Drug Recommendation System for cancer cell lines
Paper and Code
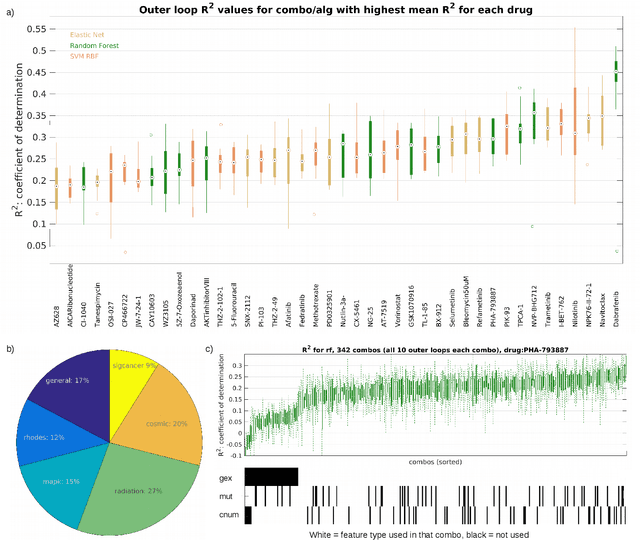
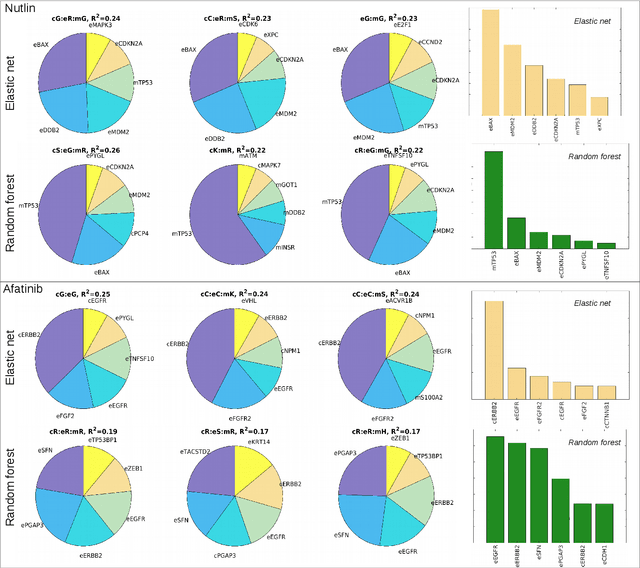
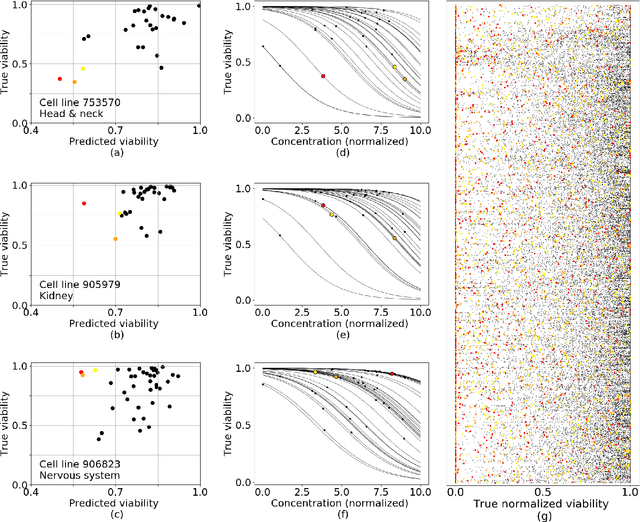
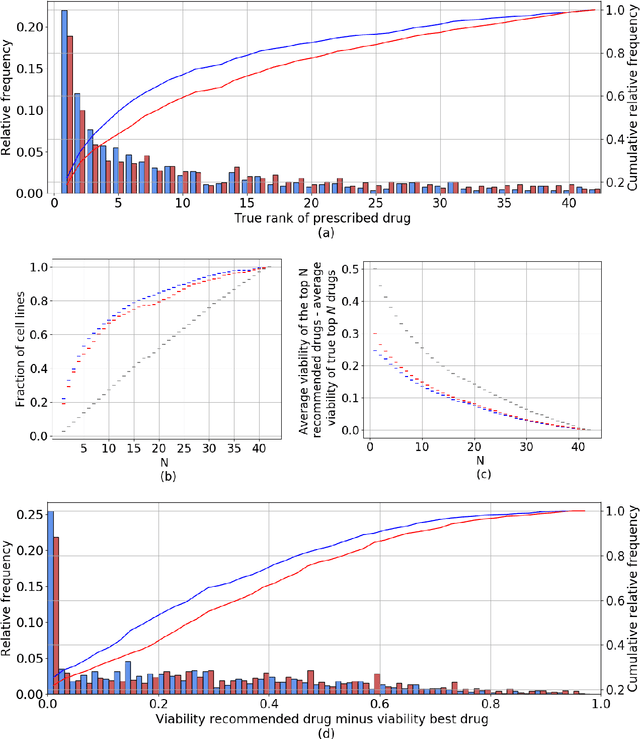
Personalizing drug prescriptions in cancer care based on genomic information requires associating genomic markers with treatment effects. This is an unsolved challenge requiring genomic patient data in yet unavailable volumes as well as appropriate quantitative methods. We attempt to solve this challenge for an experimental proxy for which sufficient data is available: 42 drugs tested on 1018 cancer cell lines. Our goal is to develop a method to identify the drug that is most promising based on a cell line's genomic information. For this, we need to identify for each drug the machine learning method, choice of hyperparameters and genomic features for optimal predictive performance. We extensively compare combinations of gene sets (both curated and random), genetic features, and machine learning algorithms for all 42 drugs. For each drug, the best performing combination (considering only the curated gene sets) is selected. We use these top model parameters for each drug to build and demonstrate a Drug Recommendation System (Dr.S). Insights resulting from this analysis are formulated as best practices for developing drug recommendation systems. The complete software system, called the Cell Line Analyzer, is written in Python and available on github.