Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Better Bound Gives a Hundred Rounds: Enhanced Privacy Guarantees via $f$-Divergences
Paper and Code
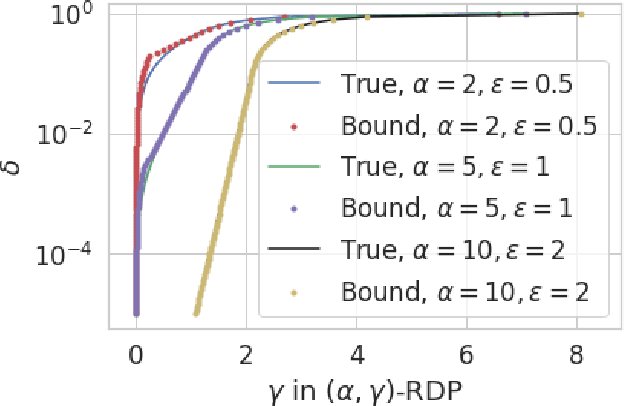
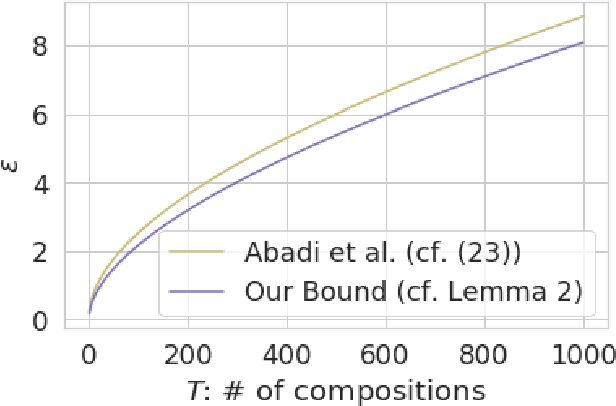
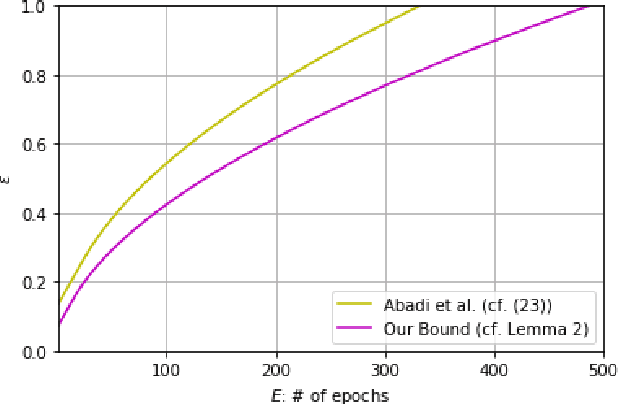
We derive the optimal differential privacy (DP) parameters of a mechanism that satisfies a given level of R\'enyi differential privacy (RDP). Our result is based on the joint range of two $f$-divergences that underlie the approximate and the R\'enyi variations of differential privacy. We apply our result to the moments accountant framework for characterizing privacy guarantees of stochastic gradient descent. When compared to the state-of-the-art, our bounds may lead to about 100 more stochastic gradient descent iterations for training deep learning models for the same privacy budget.
* Submitted for Publication
View paper on