 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeChat AI's Submission for DSTC9 Interactive Dialogue Evaluation Track
Jan 20, 2021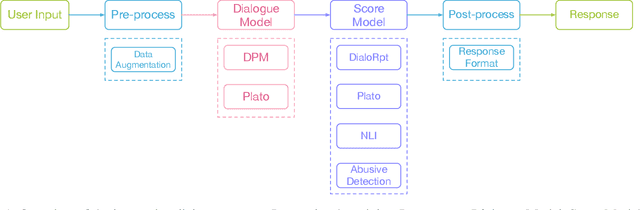


We participate in the DSTC9 Interactive Dialogue Evaluation Track (Gunasekara et al. 2020) sub-task 1 (Knowledge Grounded Dialogue) and sub-task 2 (Interactive Dialogue). In sub-task 1, we employ a pre-trained language model to generate topic-related responses and propose a response ensemble method for response selection. In sub-task2, we propose a novel Dialogue Planning Model (DPM) to capture conversation flow in the interaction with humans. We also design an integrated open-domain dialogue system containing pre-process, dialogue model, scoring model, and post-process, which can generate fluent, coherent, consistent, and humanlike responses. We tie 1st on human ratings and also get the highest Meteor, and Bert-score in sub-task 1, and rank 3rd on interactive human evaluation in sub-task 2.
Bridging Text and Video: A Universal Multimodal Transformer for Video-Audio Scene-Aware Dialog
Feb 01, 2020
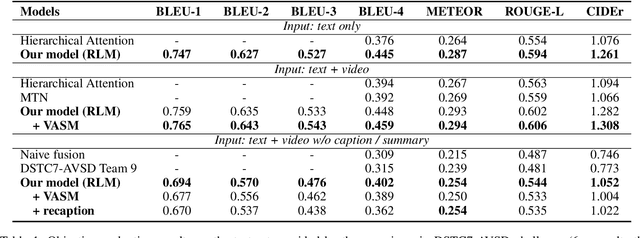

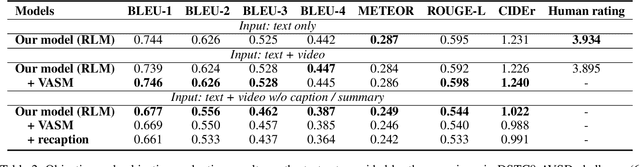
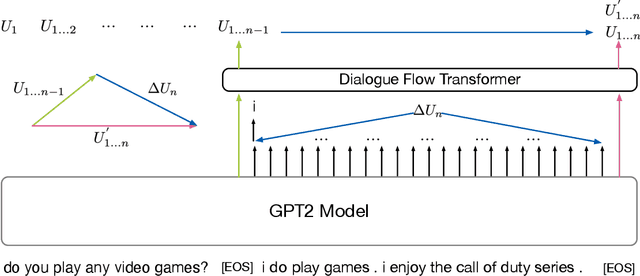
Audio-Visual Scene-Aware Dialog (AVSD) is a task to generate responses when chatting about a given video, which is organized as a track of the 8th Dialog System Technology Challenge (DSTC8). To solve the task, we propose a universal multimodal transformer and introduce the multi-task learning method to learn joint representations among different modalities as well as generate informative and fluent responses. Our method extends the natural language generation pre-trained model to multimodal dialogue generation task. Our system achieves the best performance in both objective and subjective evaluations in the challenge.