 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeizureTransformer: Scaling U-Net with Transformer for Simultaneous Time-Step Level Seizure Detection from Long EEG Recordings
Apr 02, 2025Epilepsy is a common neurological disorder that affects around 65 million people worldwide. Detecting seizures quickly and accurately is vital, given the prevalence and severity of the associated complications. Recently, deep learning-based automated seizure detection methods have emerged as solutions; however, most existing methods require extensive post-processing and do not effectively handle the crucial long-range patterns in EEG data. In this work, we propose SeizureTransformer, a simple model comprised of (i) a deep encoder comprising 1D convolutions (ii) a residual CNN stack and a transformer encoder to embed previous output into high-level representation with contextual information, and (iii) streamlined decoder which converts these features into a sequence of probabilities, directly indicating the presence or absence of seizures at every time step. Extensive experiments on public and private EEG seizure detection datasets demonstrate that our model significantly outperforms existing approaches (ranked in the first place in the 2025 "seizure detection challenge" organized in the International Conference on Artificial Intelligence in Epilepsy and Other Neurological Disorders), underscoring its potential for real-time, precise seizure detection.
Manboformer: Learning Gaussian Representations via Spatial-temporal Attention Mechanism
Mar 06, 2025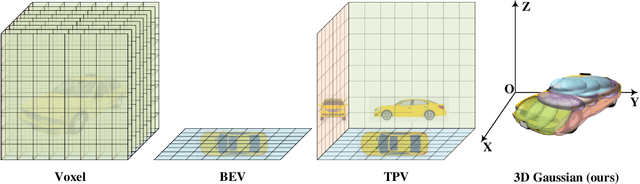


Compared with voxel-based grid prediction, in the field of 3D semantic occupation prediction for autonomous driving, GaussianFormer proposed using 3D Gaussian to describe scenes with sparse 3D semantic Gaussian based on objects is another scheme with lower memory requirements. Each 3D Gaussian function represents a flexible region of interest and its semantic features, which are iteratively refined by the attention mechanism. In the experiment, it is found that the Gaussian function required by this method is larger than the query resolution of the original dense grid network, resulting in impaired performance. Therefore, we consider optimizing GaussianFormer by using unused temporal information. We learn the Spatial-Temporal Self-attention Mechanism from the previous grid-given occupation network and improve it to GaussianFormer. The experiment was conducted with the NuScenes dataset, and the experiment is currently underway.
Coded Speech Quality Measurement by a Non-Intrusive PESQ-DNN
Apr 18, 2023



Wideband codecs such as AMR-WB or EVS are widely used in (mobile) speech communication. Evaluation of coded speech quality is often performed subjectively by an absolute category rating (ACR) listening test. However, the ACR test is impractical for online monitoring of speech communication networks. Perceptual evaluation of speech quality (PESQ) is one of the widely used metrics instrumentally predicting the results of an ACR test. However, the PESQ algorithm requires an original reference signal, which is usually unavailable in network monitoring, thus limiting its applicability. NISQA is a new non-intrusive neural-network-based speech quality measure, focusing on super-wideband speech signals. In this work, however, we aim at predicting the well-known PESQ metric using a non-intrusive PESQ-DNN model. We illustrate the potential of this model by predicting the PESQ scores of wideband-coded speech obtained from AMR-WB or EVS codecs operating at different bitrates in noisy, tandeming, and error-prone transmission conditions. We compare our methods with the state-of-the-art network topologies of QualityNet, WaweNet, and DNSMOS -- all applied to PESQ prediction -- by measuring the mean absolute error (MAE) and the linear correlation coefficient (LCC). The proposed PESQ-DNN offers the best total MAE and LCC of 0.11 and 0.92, respectively, in conditions without frame loss, and still is best when including frame loss. Note that our model could be similarly used to non-intrusively predict POLQA or other (intrusive) metrics. Upon article acceptance, code will be provided at GitHub.
Principled Pruning of Bayesian Neural Networks through Variational Free Energy Minimization
Oct 17, 2022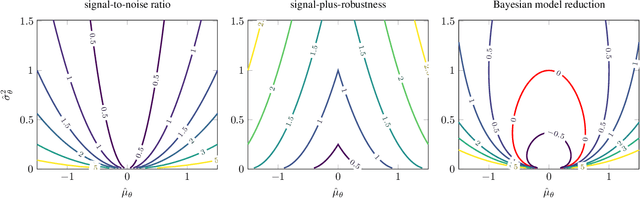


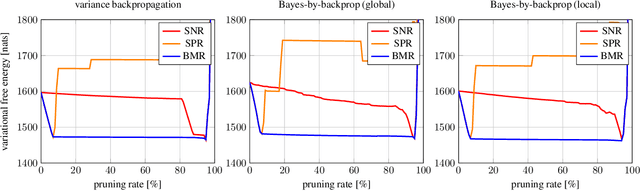
Bayesian model reduction provides an efficient approach for comparing the performance of all nested sub-models of a model, without re-evaluating any of these sub-models. Until now, Bayesian model reduction has been applied mainly in the computational neuroscience community. In this paper, we formulate and apply Bayesian model reduction to perform principled pruning of Bayesian neural networks, based on variational free energy minimization. This novel parameter pruning scheme solves the shortcomings of many current state-of-the-art pruning methods that are used by the signal processing community. The proposed approach has a clear stopping criterion and minimizes the same objective that is used during training. Next to these theoretical benefits, our experiments indicate better model performance in comparison to state-of-the-art pruning schemes.