 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipled Pruning of Bayesian Neural Networks through Variational Free Energy Minimization
Oct 17, 2022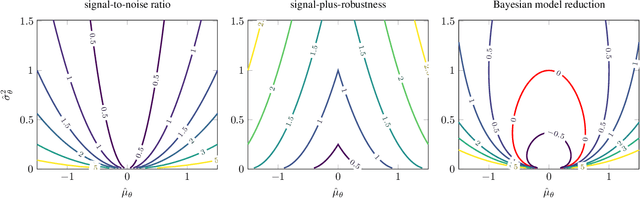


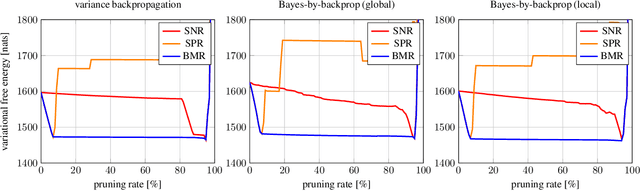
Bayesian model reduction provides an efficient approach for comparing the performance of all nested sub-models of a model, without re-evaluating any of these sub-models. Until now, Bayesian model reduction has been applied mainly in the computational neuroscience community. In this paper, we formulate and apply Bayesian model reduction to perform principled pruning of Bayesian neural networks, based on variational free energy minimization. This novel parameter pruning scheme solves the shortcomings of many current state-of-the-art pruning methods that are used by the signal processing community. The proposed approach has a clear stopping criterion and minimizes the same objective that is used during training. Next to these theoretical benefits, our experiments indicate better model performance in comparison to state-of-the-art pruning schemes.
On Sequential Bayesian Optimization with Pairwise Comparison
Mar 24, 2021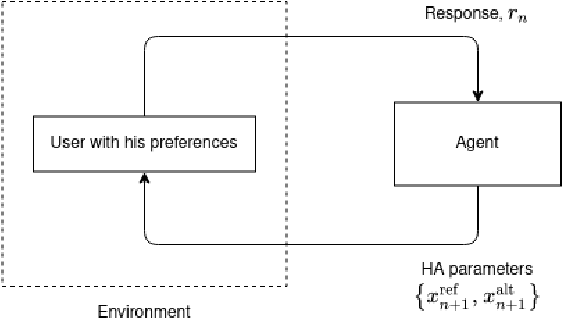
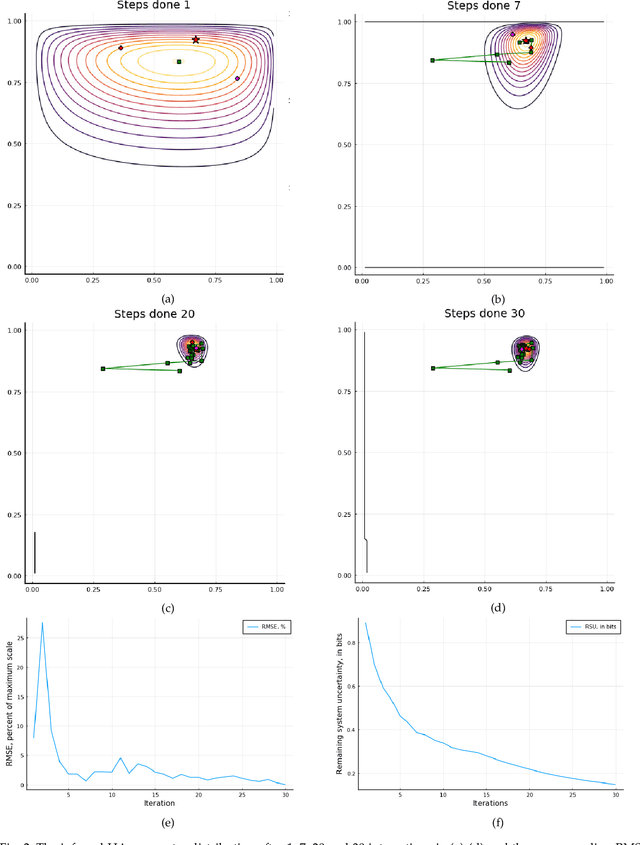
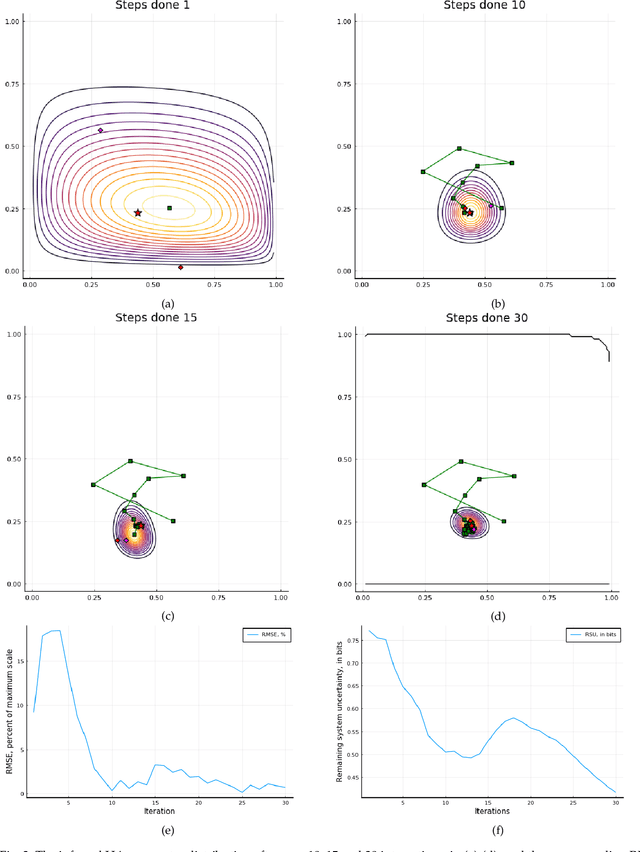
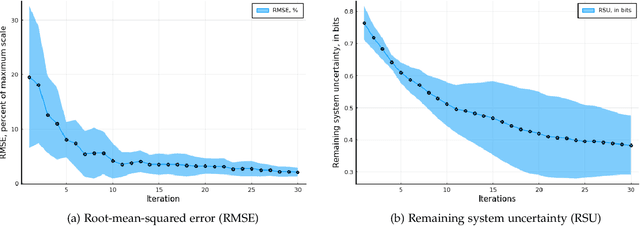
In this work, we study the problem of user preference learning on the example of parameter setting for a hearing aid (HA). We propose to use an agent that interacts with a HA user, in order to collect the most informative data, and learns user preferences for HA parameter settings, based on these data. We model the HA system as two interacting sub-systems, one representing a user with his/her preferences and another one representing an agent. In this system, the user responses to HA settings, proposed by the agent. In our user model, the responses are driven by a parametric user preference function. The agent comprises the sequential mechanisms for user model inference and HA parameter proposal generation. To infer the user model (preference function), Bayesian approximate inference is used in the agent. Here we propose the normalized weighted Kullback-Leibler (KL) divergence between true and agent-assigned predictive user response distributions as a metric to assess the quality of learned preferences. Moreover, our agent strategy for generating HA parameter proposals is to generate HA settings, responses to which help resolving uncertainty associated with prediction of the user responses the most. The resulting data, consequently, allows for efficient user model learning. The normalized weighted KL-divergence plays an important role here as well, since it characterizes the informativeness of the data to be used for probing the user. The efficiency of our approach is validated by numerical simulations.