 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization in Intent Detection: GRPO with Reward-Based Curriculum Sampling
Apr 21, 2025Intent detection, a critical component in task-oriented dialogue (TOD) systems, faces significant challenges in adapting to the rapid influx of integrable tools with complex interrelationships. Existing approaches, such as zero-shot reformulations and LLM-based dynamic recognition, struggle with performance degradation when encountering unseen intents, leading to erroneous task routing. To enhance the model's generalization performance on unseen tasks, we employ Reinforcement Learning (RL) combined with a Reward-based Curriculum Sampling (RCS) during Group Relative Policy Optimization (GRPO) training in intent detection tasks. Experiments demonstrate that RL-trained models substantially outperform supervised fine-tuning (SFT) baselines in generalization. Besides, the introduction of the RCS, significantly bolsters the effectiveness of RL in intent detection by focusing the model on challenging cases during training. Moreover, incorporating Chain-of-Thought (COT) processes in RL notably improves generalization in complex intent detection tasks, underscoring the importance of thought in challenging scenarios. This work advances the generalization of intent detection tasks, offering practical insights for deploying adaptable dialogue systems.
Learning to Generate Structured Queries from Natural Language with Indirect Supervision
Sep 10, 2018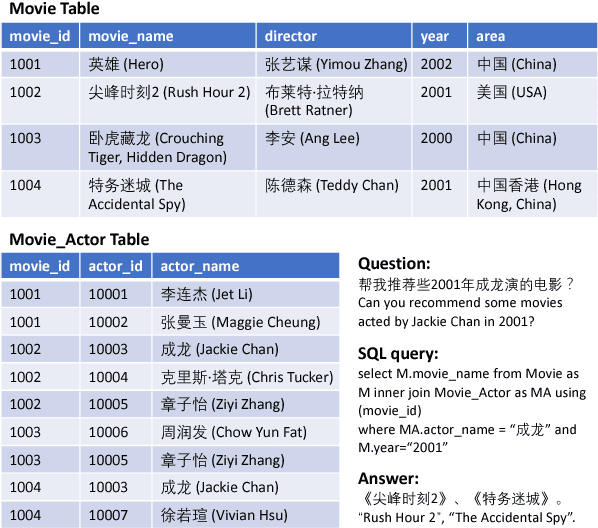
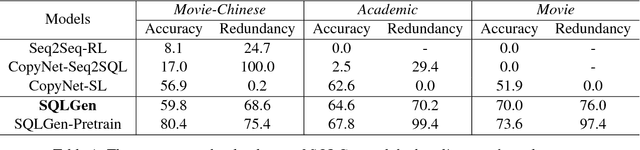
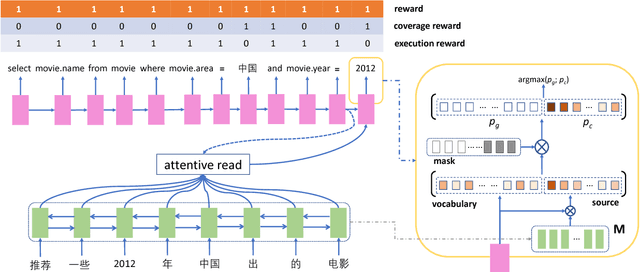
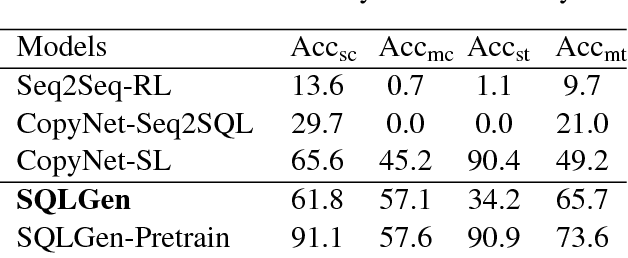
Generating structured query language (SQL) from natural language is an emerging research topic. This paper presents a new learning paradigm from indirect supervision of the answers to natural language questions, instead of SQL queries. This paradigm facilitates the acquisition of training data due to the abundant resources of question-answer pairs for various domains in the Internet, and expels the difficult SQL annotation job. An end-to-end neural model integrating with reinforcement learning is proposed to learn SQL generation policy within the answer-driven learning paradigm. The model is evaluated on datasets of different domains, including movie and academic publication. Experimental results show that our model outperforms the baseline models.