 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Survey of Model Compression and Speed up for Vision Transformers
Apr 16, 2024Vision Transformers (ViT) have marked a paradigm shift in computer vision, outperforming state-of-the-art models across diverse tasks. However, their practical deployment is hampered by high computational and memory demands. This study addresses the challenge by evaluating four primary model compression techniques: quantization, low-rank approximation, knowledge distillation, and pruning. We methodically analyze and compare the efficacy of these techniques and their combinations in optimizing ViTs for resource-constrained environments. Our comprehensive experimental evaluation demonstrates that these methods facilitate a balanced compromise between model accuracy and computational efficiency, paving the way for wider application in edge computing devices.
Machine learning-based system reliability analysis with Gaussian Process Regression
Mar 17, 2024Machine learning-based reliability analysis methods have shown great advancements for their computational efficiency and accuracy. Recently, many efficient learning strategies have been proposed to enhance the computational performance. However, few of them explores the theoretical optimal learning strategy. In this article, we propose several theorems that facilitates such exploration. Specifically, cases that considering and neglecting the correlations among the candidate design samples are well elaborated. Moreover, we prove that the well-known U learning function can be reformulated to the optimal learning function for the case neglecting the Kriging correlation. In addition, the theoretical optimal learning strategy for sequential multiple training samples enrichment is also mathematically explored through the Bayesian estimate with the corresponding lost functions. Simulation results show that the optimal learning strategy considering the Kriging correlation works better than that neglecting the Kriging correlation and other state-of-the art learning functions from the literatures in terms of the reduction of number of evaluations of performance function. However, the implementation needs to investigate very large computational resource.
Deep Learning-Based Strategy for Macromolecules Classification with Imbalanced Data from Cellular Electron Cryotomography
Aug 27, 2019



Deep learning model trained by imbalanced data may not work satisfactorily since it could be determined by major classes and thus may ignore the classes with small amount of data. In this paper, we apply deep learning based imbalanced data classification for the first time to cellular macromolecular complexes captured by Cryo-electron tomography (Cryo-ET). We adopt a range of strategies to cope with imbalanced data, including data sampling, bagging, boosting, Genetic Programming based method and. Particularly, inspired from Inception 3D network, we propose a multi-path CNN model combining focal loss and mixup on the Cryo-ET dataset to expand the dataset, where each path had its best performance corresponding to each type of data and let the network learn the combinations of the paths to improve the classification performance. In addition, extensive experiments have been conducted to show our proposed method is flexible enough to cope with different number of classes by adjusting the number of paths in our multi-path model. To our knowledge, this work is the first application of deep learning methods of dealing with imbalanced data to the internal tissue classification of cell macromolecular complexes, which opened up a new path for cell classification in the field of computational biology.
* 13 pages. arXiv admin note: text overlap with arXiv:1710.09412, arXiv:1710.05381, arXiv:1708.02002 by other authors
Sentiment Analysis using Deep Robust Complementary Fusion of Multi-Features and Multi-Modalities
Apr 25, 2019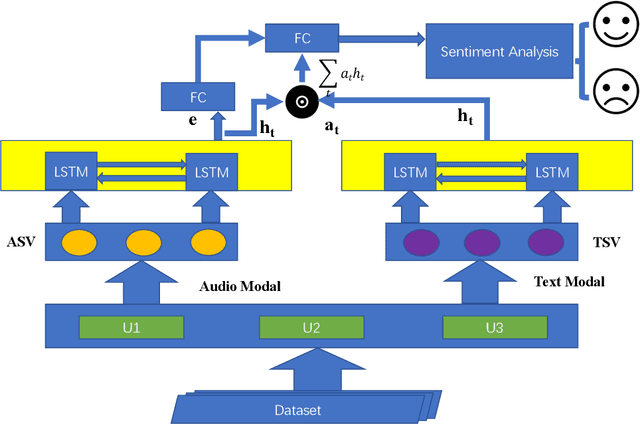



Sentiment analysis research has been rapidly developing in the last decade and has attracted widespread attention from academia and industry, most of which is based on text. However, the information in the real world usually comes as different modalities. In this paper, we consider the task of Multimodal Sentiment Analysis, using Audio and Text Modalities, proposed a novel fusion strategy including Multi-Feature Fusion and Multi-Modality Fusion to improve the accuracy of Audio-Text Sentiment Analysis. We call this the Deep Feature Fusion-Audio and Text Modal Fusion (DFF-ATMF) model, and the features learned from it are complementary to each other and robust. Experiments with the CMU-MOSI corpus and the recently released CMU-MOSEI corpus for Youtube video sentiment analysis show the very competitive results of our proposed model. Surprisingly, our method also achieved the state-of-the-art results in the IEMOCAP dataset, indicating that our proposed fusion strategy is also extremely generalization ability to Multimodal Emotion Recognition.
Utterance-Based Audio Sentiment Analysis Learned by a Parallel Combination of CNN and LSTM
Nov 20, 2018



Audio Sentiment Analysis is a popular research area which extends the conventional text-based sentiment analysis to depend on the effectiveness of acoustic features extracted from speech. However, current progress on audio sentiment analysis mainly focuses on extracting homogeneous acoustic features or doesn't fuse heterogeneous features effectively. In this paper, we propose an utterance-based deep neural network model, which has a parallel combination of Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) based network, to obtain representative features termed Audio Sentiment Vector (ASV), that can maximally reflect sentiment information in an audio. Specifically, our model is trained by utterance-level labels and ASV can be extracted and fused creatively from two branches. In the CNN model branch, spectrum graphs produced by signals are fed as inputs while in the LSTM model branch, inputs include spectral features and cepstrum coefficient extracted from dependent utterances in an audio. Besides, Bidirectional Long Short-Term Memory (BiLSTM) with attention mechanism is used for feature fusion. Extensive experiments have been conducted to show our model can recognize audio sentiment precisely and quickly, and demonstrate our ASV are better than traditional acoustic features or vectors extracted from other deep learning models. Furthermore, experimental results indicate that the proposed model outperforms the state-of-the-art approach by 9.33% on Multimodal Opinion-level Sentiment Intensity dataset (MOSI) dataset.