 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment Analysis using Deep Robust Complementary Fusion of Multi-Features and Multi-Modalities
Paper and Code
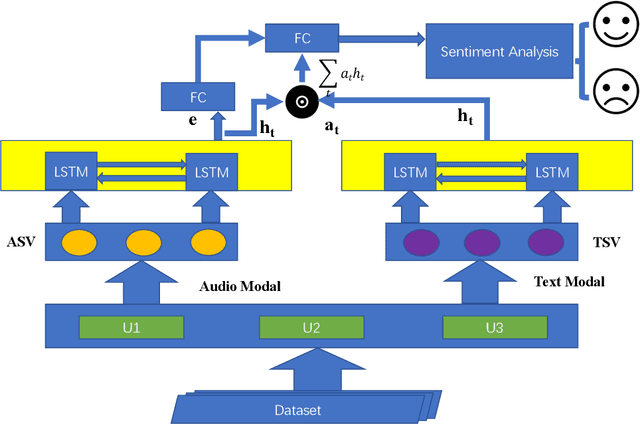



Sentiment analysis research has been rapidly developing in the last decade and has attracted widespread attention from academia and industry, most of which is based on text. However, the information in the real world usually comes as different modalities. In this paper, we consider the task of Multimodal Sentiment Analysis, using Audio and Text Modalities, proposed a novel fusion strategy including Multi-Feature Fusion and Multi-Modality Fusion to improve the accuracy of Audio-Text Sentiment Analysis. We call this the Deep Feature Fusion-Audio and Text Modal Fusion (DFF-ATMF) model, and the features learned from it are complementary to each other and robust. Experiments with the CMU-MOSI corpus and the recently released CMU-MOSEI corpus for Youtube video sentiment analysis show the very competitive results of our proposed model. Surprisingly, our method also achieved the state-of-the-art results in the IEMOCAP dataset, indicating that our proposed fusion strategy is also extremely generalization ability to Multimodal Emotion Recognition.