 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Hierarchical GRPO: Decoupling Tool Invocation from Execution for Tool-Integrated Mathematical Reasoning
May 18, 2026Large language models (LLMs) have increasingly leveraged tool invocation to enhance their reasoning capabilities. However, existing approaches typically tightly couple tool invocation with immediate execution. Such immediate tool interaction may disrupt the reasoning coherence of LLMs and constrain their expressivity, ultimately degrading reasoning performance. To this end, for the first time, we propose and formalize the problem of decoupling tool invocation from execution during reasoning, and introduce delayed execution with explicit control to enhance tool-integrated reasoning (TIR). Furthermore, we propose a hierarchical control framework and theoretically derive a surrogate loss that enables an implicitly hierarchical policy to learn behavior equivalent to that of an explicit hierarchical policy, leading to the proposed IH-GRPO algorithm. Extensive experiments on IH-GRPO achieve absolute improvements of 1.87\%, 2.16\%, and 2.53\% on Qwen3-1.7B, Qwen3-4B, and Qwen3-8B across six out-of-domain mathematical reasoning benchmarks over the strongest baseline method, while also yielding consistent performance gains in other domains. Our code is available at https://github.com/Lumina04/IH-GRPO-01.
Qwen2.5-1M Technical Report
Jan 26, 2025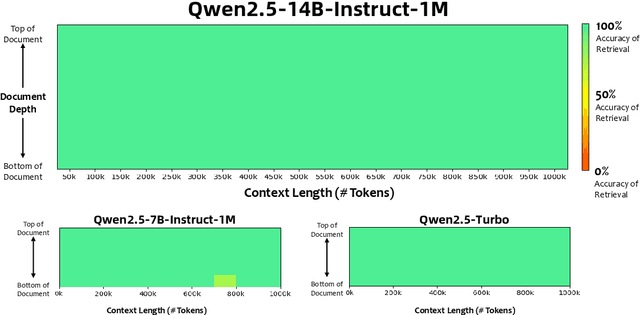

We introduce Qwen2.5-1M, a series of models that extend the context length to 1 million tokens. Compared to the previous 128K version, the Qwen2.5-1M series have significantly enhanced long-context capabilities through long-context pre-training and post-training. Key techniques such as long data synthesis, progressive pre-training, and multi-stage supervised fine-tuning are employed to effectively enhance long-context performance while reducing training costs. To promote the use of long-context models among a broader user base, we present and open-source our inference framework. This framework includes a length extrapolation method that can expand the model context lengths by at least four times, or even more, without additional training. To reduce inference costs, we implement a sparse attention method along with chunked prefill optimization for deployment scenarios and a sparsity refinement method to improve precision. Additionally, we detail our optimizations in the inference engine, including kernel optimization, pipeline parallelism, and scheduling optimization, which significantly enhance overall inference performance. By leveraging our inference framework, the Qwen2.5-1M models achieve a remarkable 3x to 7x prefill speedup in scenarios with 1 million tokens of context. This framework provides an efficient and powerful solution for developing applications that require long-context processing using open-source models. The Qwen2.5-1M series currently includes the open-source models Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M, as well as the API-accessed model Qwen2.5-Turbo. Evaluations show that Qwen2.5-1M models have been greatly improved in long-context tasks without compromising performance in short-context scenarios. Specifically, the Qwen2.5-14B-Instruct-1M model significantly outperforms GPT-4o-mini in long-context tasks and supports contexts eight times longer.
A Nonlinear African Vulture Optimization Algorithm Combining Henon Chaotic Mapping Theory and Reverse Learning Competition Strategy
Mar 26, 2024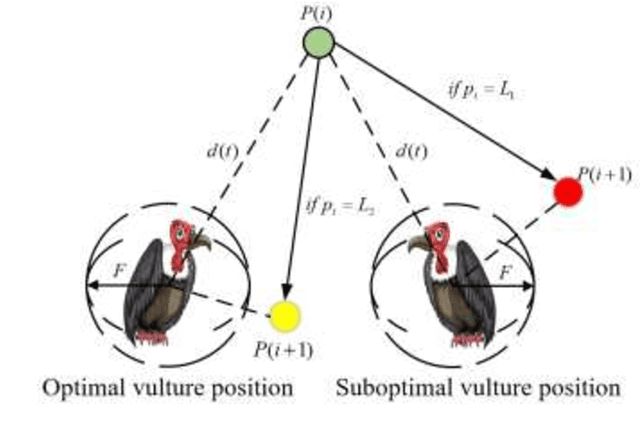



In order to alleviate the main shortcomings of the AVOA, a nonlinear African vulture optimization algorithm combining Henon chaotic mapping theory and reverse learning competition strategy (HWEAVOA) is proposed. Firstly, the Henon chaotic mapping theory and elite population strategy are proposed to improve the randomness and diversity of the vulture's initial population; Furthermore, the nonlinear adaptive incremental inertial weight factor is introduced in the location update phase to rationally balance the exploration and exploitation abilities, and avoid individual falling into a local optimum; The reverse learning competition strategy is designed to expand the discovery fields for the optimal solution and strengthen the ability to jump out of the local optimal solution. HWEAVOA and other advanced comparison algorithms are used to solve classical and CEC2022 test functions. Compared with other algorithms, the convergence curves of the HWEAVOA drop faster and the line bodies are smoother. These experimental results show the proposed HWEAVOA is ranked first in all test functions, which is superior to the comparison algorithms in convergence speed, optimization ability, and solution stability. Meanwhile, HWEAVOA has reached the general level in the algorithm complexity, and its overall performance is competitive in the swarm intelligence algorithms.