 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefense-guided Transferable Adversarial Attacks
Nov 04, 2020
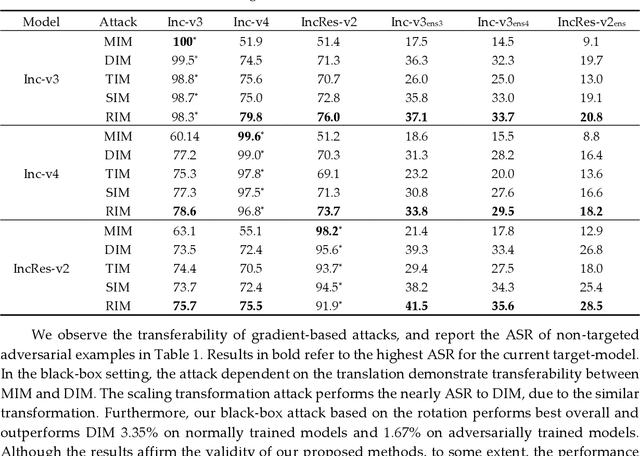


Though deep neural networks perform challenging tasks excellently, they are susceptible to adversarial examples, which mislead classifiers by applying human-imperceptible perturbations on clean inputs. Under the query-free black-box scenario, adversarial examples are hard to transfer to unknown models, and several methods have been proposed with the low transferability. To settle such issue, we design a max-min framework inspired by input transformations, which are benificial to both the adversarial attack and defense. Explicitly, we decrease loss values with inputs' affline transformations as a defense in the minimum procedure, and then increase loss values with the momentum iterative algorithm as an attack in the maximum procedure. To further promote transferability, we determine transformed values with the max-min theory. Extensive experiments on Imagenet demonstrate that our defense-guided transferable attacks achieve impressive increase on transferability. Experimentally, we show that our ASR of adversarial attack reaches to 58.38% on average, which outperforms the state-of-the-art method by 12.1% on the normally trained models and by 11.13% on the adversarially trained models. Additionally, we provide elucidative insights on the improvement of transferability, and our method is expected to be a benchmark for assessing the robustness of deep models.
AdvJND: Generating Adversarial Examples with Just Noticeable Difference
Feb 01, 2020

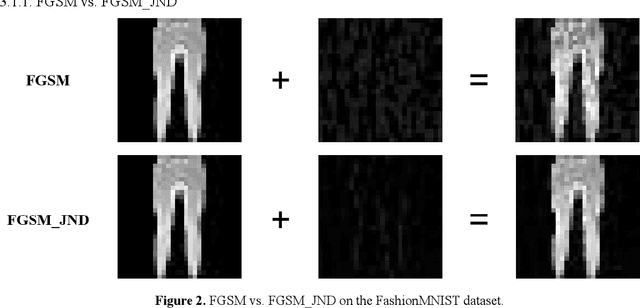
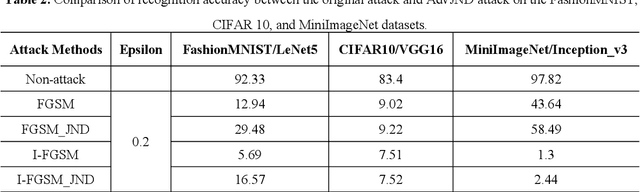
Compared with traditional machine learning models, deep neural networks perform better, especially in image classification tasks. However, they are vulnerable to adversarial examples. Adding small perturbations on examples causes a good-performance model to misclassify the crafted examples, without category differences in the human eyes, and fools deep models successfully. There are two requirements for generating adversarial examples: the attack success rate and image fidelity metrics. Generally, perturbations are increased to ensure the adversarial examples' high attack success rate; however, the adversarial examples obtained have poor concealment. To alleviate the tradeoff between the attack success rate and image fidelity, we propose a method named AdvJND, adding visual model coefficients, just noticeable difference coefficients, in the constraint of a distortion function when generating adversarial examples. In fact, the visual subjective feeling of the human eyes is added as a priori information, which decides the distribution of perturbations, to improve the image quality of adversarial examples. We tested our method on the FashionMNIST, CIFAR10, and MiniImageNet datasets. Adversarial examples generated by our AdvJND algorithm yield gradient distributions that are similar to those of the original inputs. Hence, the crafted noise can be hidden in the original inputs, thus improving the attack concealment significantly.