 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPBalance: Efficient and Fair Privacy Budget Scheduling for Federated Learning as a Service
Feb 15, 2024
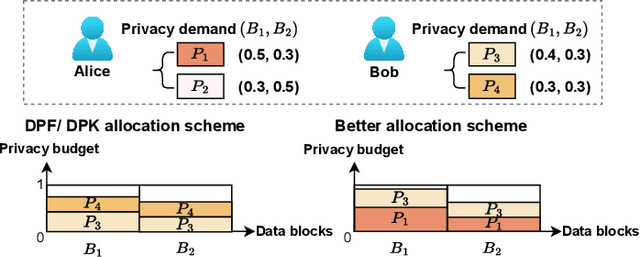
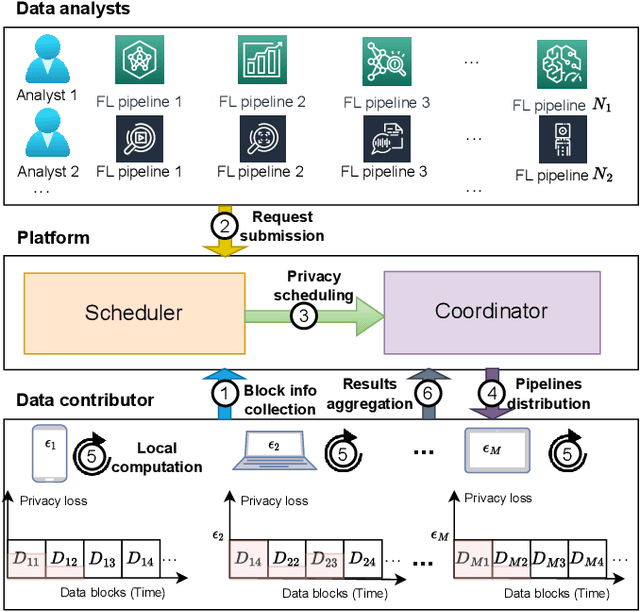
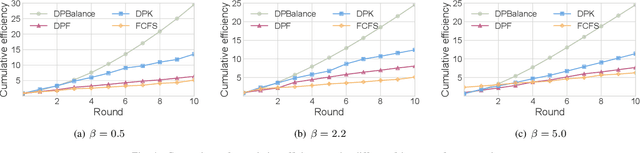
Federated learning (FL) has emerged as a prevalent distributed machine learning scheme that enables collaborative model training without aggregating raw data. Cloud service providers further embrace Federated Learning as a Service (FLaaS), allowing data analysts to execute their FL training pipelines over differentially-protected data. Due to the intrinsic properties of differential privacy, the enforced privacy level on data blocks can be viewed as a privacy budget that requires careful scheduling to cater to diverse training pipelines. Existing privacy budget scheduling studies prioritize either efficiency or fairness individually. In this paper, we propose DPBalance, a novel privacy budget scheduling mechanism that jointly optimizes both efficiency and fairness. We first develop a comprehensive utility function incorporating data analyst-level dominant shares and FL-specific performance metrics. A sequential allocation mechanism is then designed using the Lagrange multiplier method and effective greedy heuristics. We theoretically prove that DPBalance satisfies Pareto Efficiency, Sharing Incentive, Envy-Freeness, and Weak Strategy Proofness. We also theoretically prove the existence of a fairness-efficiency tradeoff in privacy budgeting. Extensive experiments demonstrate that DPBalance outperforms state-of-the-art solutions, achieving an average efficiency improvement of $1.44\times \sim 3.49 \times$, and an average fairness improvement of $1.37\times \sim 24.32 \times$.
Autothrust: A Practical Framework for Harvesting CPUs from SLO-Targeted Microservices
Jan 06, 2023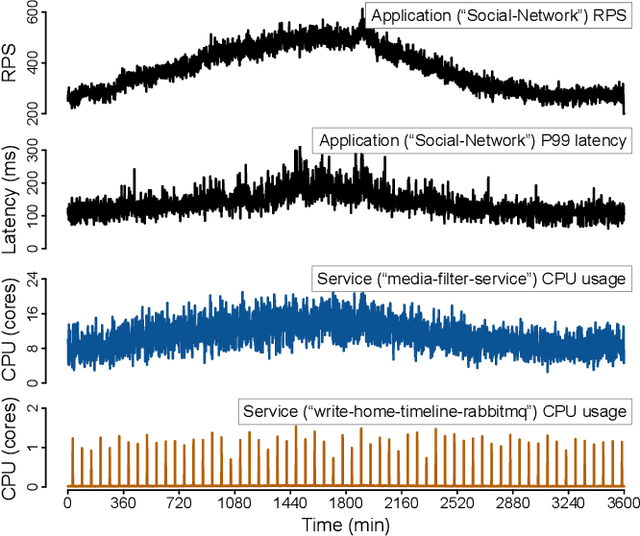
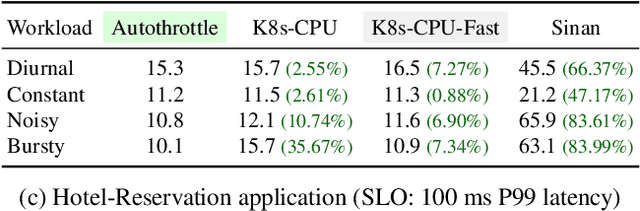
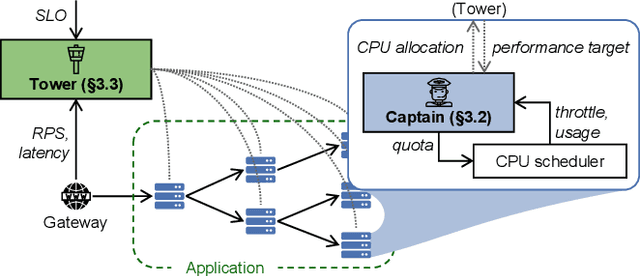

As the number of distributed services (or microservices) of cloud-native applications grows, resource management becomes a challenging task. These applications tend to be user-facing and latency-sensitive, and our goal is to continuously minimize the amount of CPU resources allocated while still satisfying the application latency SLO. Although previous efforts have proposed simple heuristics and sophisticated ML-based techniques, we believe that a practical resource manager should accurately scale CPU resources for diverse applications, with minimum human efforts and operation overheads. To this end, we ask: can we systematically break resource management down to subproblems solvable by practical policies? Based on the notion of CPU-throttle-based performance target, we decouple the mechanisms of SLO feedback and resource control, and implement a two-level framework -- Autothrust. It combines a lightweight learned controller at the global level, and agile per-microservice controllers at the local level. We evaluate Autothrust on three microservice applications, with both short-term and 21-day production workload traces. Empirical results show Autothrust's superior CPU core savings up to 26.21% over the best-performing baselines across applications, while maintaining the latency SLO.