 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutothrust: A Practical Framework for Harvesting CPUs from SLO-Targeted Microservices
Paper and Code
Jan 06, 2023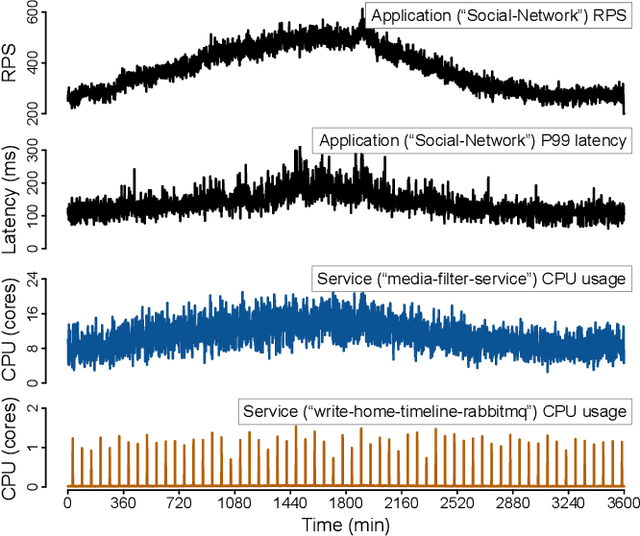
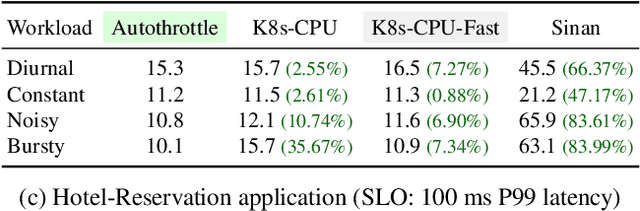
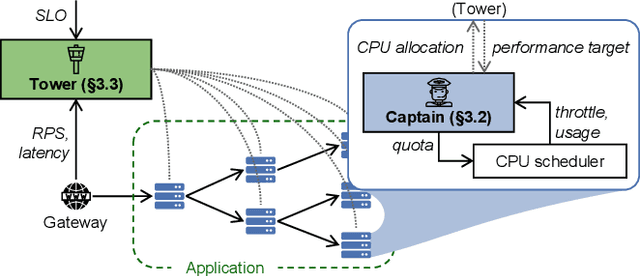

As the number of distributed services (or microservices) of cloud-native applications grows, resource management becomes a challenging task. These applications tend to be user-facing and latency-sensitive, and our goal is to continuously minimize the amount of CPU resources allocated while still satisfying the application latency SLO. Although previous efforts have proposed simple heuristics and sophisticated ML-based techniques, we believe that a practical resource manager should accurately scale CPU resources for diverse applications, with minimum human efforts and operation overheads. To this end, we ask: can we systematically break resource management down to subproblems solvable by practical policies? Based on the notion of CPU-throttle-based performance target, we decouple the mechanisms of SLO feedback and resource control, and implement a two-level framework -- Autothrust. It combines a lightweight learned controller at the global level, and agile per-microservice controllers at the local level. We evaluate Autothrust on three microservice applications, with both short-term and 21-day production workload traces. Empirical results show Autothrust's superior CPU core savings up to 26.21% over the best-performing baselines across applications, while maintaining the latency SLO.