 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Label Propagation for Multi-relational Learning on Tensor Product Graph
Feb 20, 2018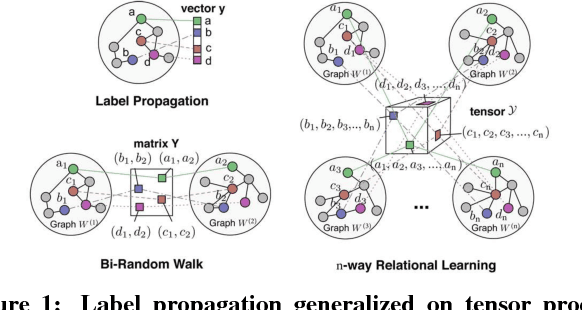
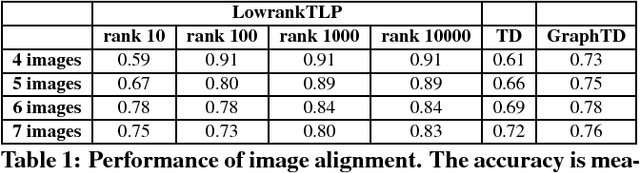
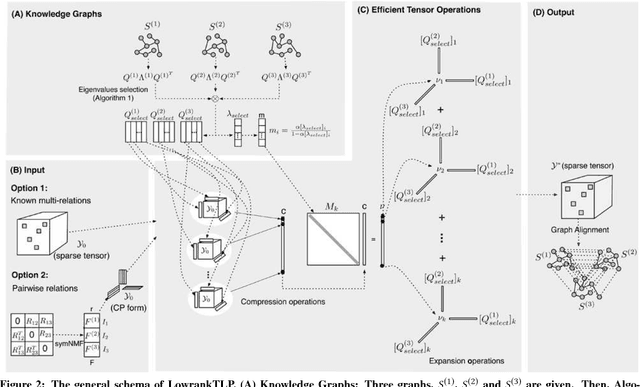
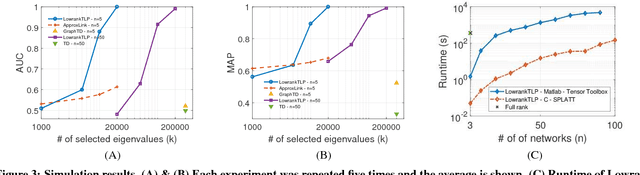
Label propagation on the tensor product of multiple graphs can infer multi-relations among the entities across the graphs by learning labels in a tensor. However, the tensor formulation is only empirically scalable up to three graphs due to the exponential complexity of computing tensors. In this paper, we propose an optimization formulation and a scalable Lowrank Tensor-based Label Propagation algorithm (LowrankTLP). The optimization formulation minimizes the rank-k approximation error for computing the closed-form solution of label propagation on a tensor product graph with efficient tensor computations used in LowrankTLP. LowrankTLP takes either a sparse tensor of known multi-relations or pairwise relations between each pair of graphs as the input to infer unknown multi-relations by semi-supervised learning on the tensor product graph. We also accelerate LowrankTLP with parallel tensor computation which enabled label propagation on a tensor product of 100 graphs of size 1000 within 150 seconds in simulation. LowrankTLP was also successfully applied to multi-relational learning for predicting author-paper-venue in publication records, alignment of several protein-protein interaction networks across species and alignment of segmented regions across up to 7 CT scan images. The experiments prove that LowrankTLP indeed well approximates the original label propagation with high scalability. Source code: https://github.com/kuanglab/LowrankTLP
Low-rank Label Propagation for Semi-supervised Learning with 100 Millions Samples
Feb 28, 2017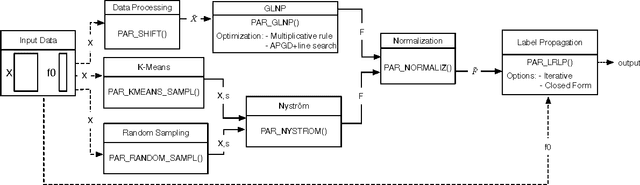

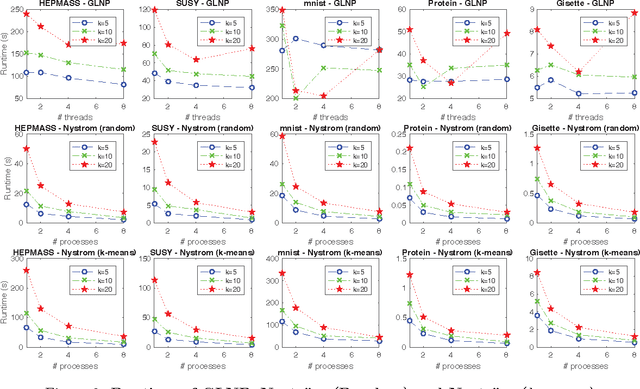
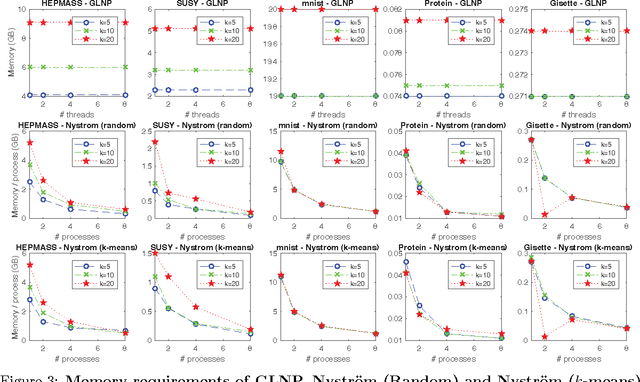
The success of semi-supervised learning crucially relies on the scalability to a huge amount of unlabelled data that are needed to capture the underlying manifold structure for better classification. Since computing the pairwise similarity between the training data is prohibitively expensive in most kinds of input data, currently, there is no general ready-to-use semi-supervised learning method/tool available for learning with tens of millions or more data points. In this paper, we adopted the idea of two low-rank label propagation algorithms, GLNP (Global Linear Neighborhood Propagation) and Kernel Nystr\"om Approximation, and implemented the parallelized version of the two algorithms accelerated with Nesterov's accelerated projected gradient descent for Big-data Label Propagation (BigLP). The parallel algorithms are tested on five real datasets ranging from 7000 to 10,000,000 in size and a simulation dataset of 100,000,000 samples. In the experiments, the implementation can scale up to datasets with 100,000,000 samples and hundreds of features and the algorithms also significantly improved the prediction accuracy when only a very small percentage of the data is labeled. The results demonstrate that the BigLP implementation is highly scalable to big data and effective in utilizing the unlabeled data for semi-supervised learning.