 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Targeted Clean-Label Poisoning Attacks Generalize?
Dec 05, 2024


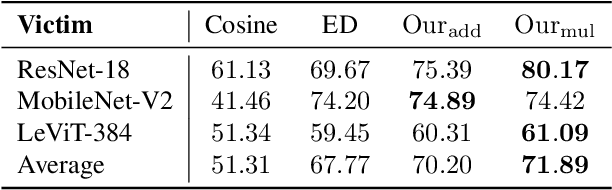
Targeted poisoning attacks aim to compromise the model's prediction on specific target samples. In a common clean-label setting, they are achieved by slightly perturbing a subset of training samples given access to those specific targets. Despite continuous efforts, it remains unexplored whether such attacks can generalize to unknown variations of those targets. In this paper, we take the first step to systematically study this generalization problem. Observing that the widely adopted, cosine similarity-based attack exhibits limited generalizability, we propose a well-generalizable attack that leverages both the direction and magnitude of model gradients. In particular, we explore diverse target variations, such as an object with varied viewpoints and an animal species with distinct appearances. Extensive experiments across various generalization scenarios demonstrate that our method consistently achieves the best attack effectiveness. For example, our method outperforms the cosine similarity-based attack by 20.95% in attack success rate with similar overall accuracy, averaged over four models on two image benchmark datasets. The code is available at https://github.com/jiaangk/generalizable_tcpa