 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniTabBench: Mapping the Empirical Frontiers of GBDTs, Neural Networks, and Foundation Models for Tabular Data at Scale
Apr 08, 2026While traditional tree-based ensemble methods have long dominated tabular tasks, deep neural networks and emerging foundation models have challenged this primacy, yet no consensus exists on a universally superior paradigm. Existing benchmarks typically contain fewer than 100 datasets, raising concerns about evaluation sufficiency and potential selection biases. To address these limitations, we introduce OmniTabBench, the largest tabular benchmark to date, comprising 3030 datasets spanning diverse tasks that are comprehensively collected from diverse sources and categorized by industry using large language models. We conduct an unprecedented large-scale empirical evaluation of state-of-the-art models from all model families on OmniTabBench, confirming the absence of a dominant winner. Furthermore, through a decoupled metafeature analysis, which examines individual properties such as dataset size, feature types, feature and target skewness/kurtosis, we elucidate conditions favoring specific model categories, providing clearer, more actionable guidance than prior compound-metric studies.
Desirable Companion for Vertical Federated Learning: New Zeroth-Order Gradient Based Algorithm
Mar 19, 2022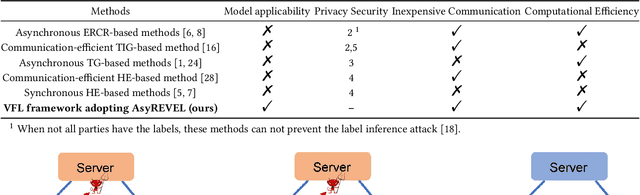
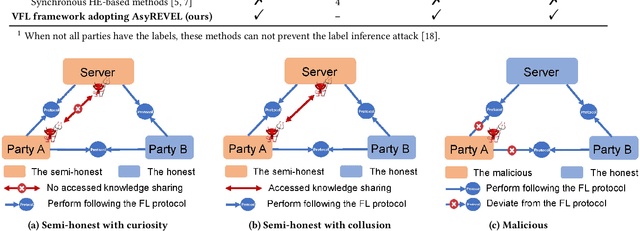
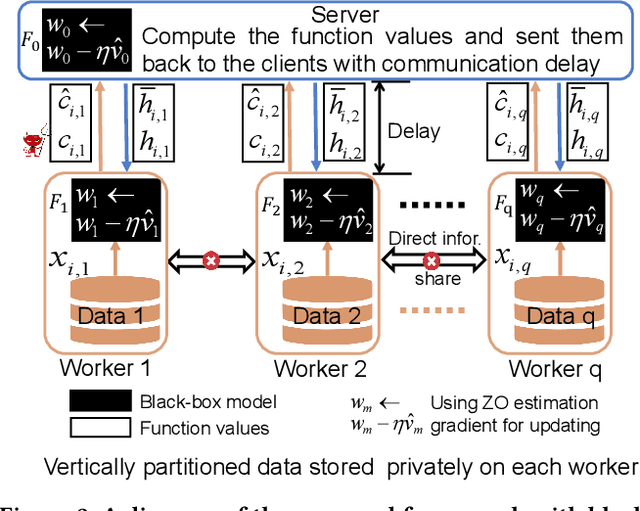
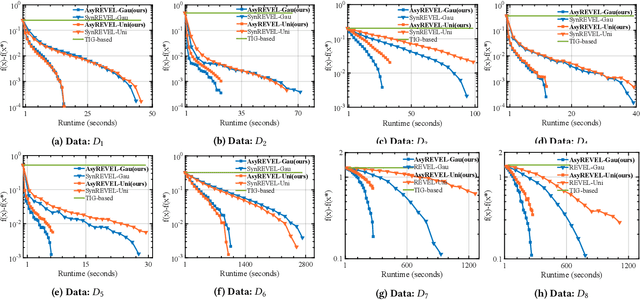
Vertical federated learning (VFL) attracts increasing attention due to the emerging demands of multi-party collaborative modeling and concerns of privacy leakage. A complete list of metrics to evaluate VFL algorithms should include model applicability, privacy security, communication cost, and computation efficiency, where privacy security is especially important to VFL. However, to the best of our knowledge, there does not exist a VFL algorithm satisfying all these criteria very well. To address this challenging problem, in this paper, we reveal that zeroth-order optimization (ZOO) is a desirable companion for VFL. Specifically, ZOO can 1) improve the model applicability of VFL framework, 2) prevent VFL framework from privacy leakage under curious, colluding, and malicious threat models, 3) support inexpensive communication and efficient computation. Based on that, we propose a novel and practical VFL framework with black-box models, which is inseparably interconnected to the promising properties of ZOO. We believe that it takes one stride towards designing a practical VFL framework matching all the criteria. Under this framework, we raise two novel {\bf asy}nchronous ze{\bf r}oth-ord{\bf e}r algorithms for {\bf v}ertical f{\bf e}derated {\bf l}earning (AsyREVEL) with different smoothing techniques. We theoretically drive the convergence rates of AsyREVEL algorithms under nonconvex condition. More importantly, we prove the privacy security of our proposed framework under existing VFL attacks on different levels. Extensive experiments on benchmark datasets demonstrate the favorable model applicability, satisfied privacy security, inexpensive communication, efficient computation, scalability and losslessness of our framework.
Doubly Contrastive Deep Clustering
Mar 09, 2021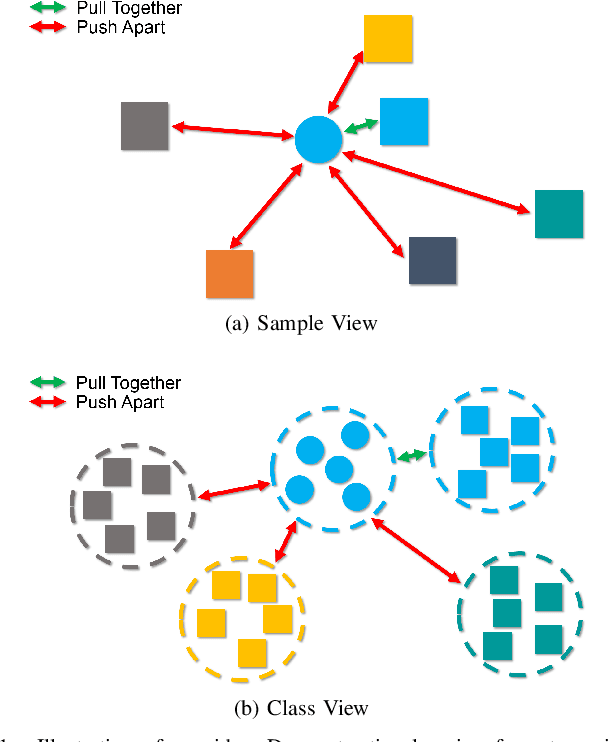
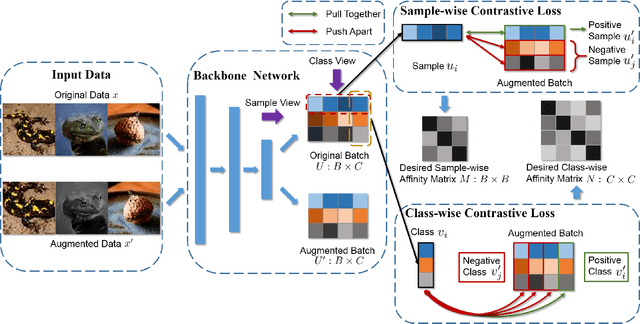
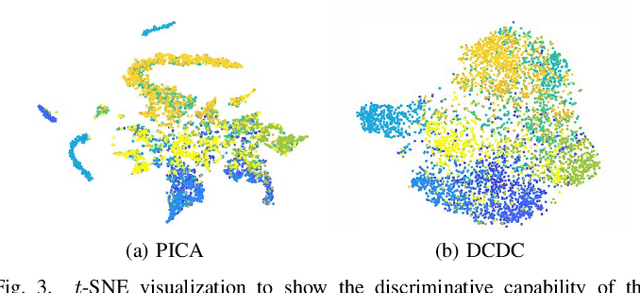
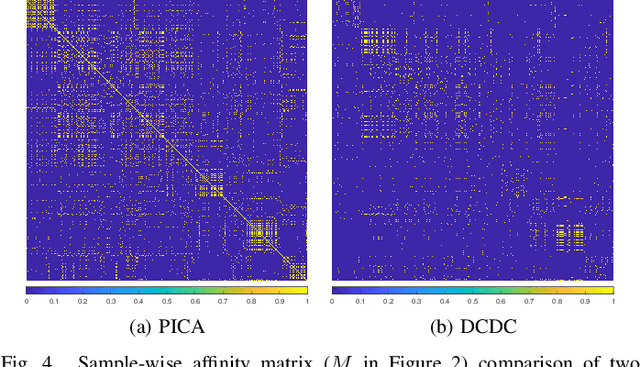
Deep clustering successfully provides more effective features than conventional ones and thus becomes an important technique in current unsupervised learning. However, most deep clustering methods ignore the vital positive and negative pairs introduced by data augmentation and further the significance of contrastive learning, which leads to suboptimal performance. In this paper, we present a novel Doubly Contrastive Deep Clustering (DCDC) framework, which constructs contrastive loss over both sample and class views to obtain more discriminative features and competitive results. Specifically, for the sample view, we set the class distribution of the original sample and its augmented version as positive sample pairs and set one of the other augmented samples as negative sample pairs. After that, we can adopt the sample-wise contrastive loss to pull positive sample pairs together and push negative sample pairs apart. Similarly, for the class view, we build the positive and negative pairs from the sample distribution of the class. In this way, two contrastive losses successfully constrain the clustering results of mini-batch samples in both sample and class level. Extensive experimental results on six benchmark datasets demonstrate the superiority of our proposed model against state-of-the-art methods. Particularly in the challenging dataset Tiny-ImageNet, our method leads 5.6\% against the latest comparison method. Our code will be available at \url{https://github.com/ZhiyuanDang/DCDC}.
Federated Doubly Stochastic Kernel Learning for Vertically Partitioned Data
Aug 14, 2020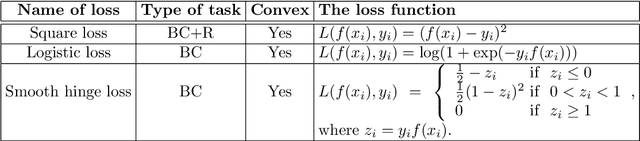
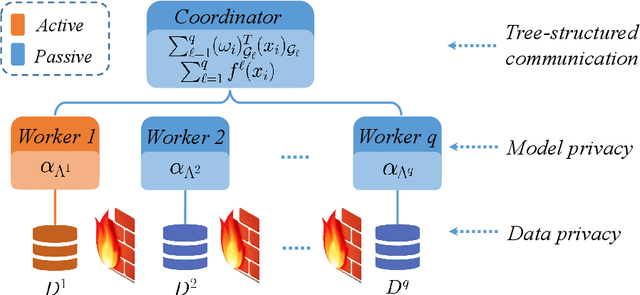
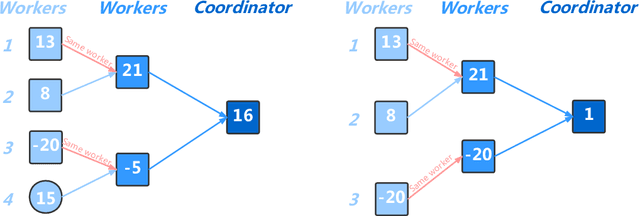

In a lot of real-world data mining and machine learning applications, data are provided by multiple providers and each maintains private records of different feature sets about common entities. It is challenging to train these vertically partitioned data effectively and efficiently while keeping data privacy for traditional data mining and machine learning algorithms. In this paper, we focus on nonlinear learning with kernels, and propose a federated doubly stochastic kernel learning (FDSKL) algorithm for vertically partitioned data. Specifically, we use random features to approximate the kernel mapping function and use doubly stochastic gradients to update the solutions, which are all computed federatedly without the disclosure of data. Importantly, we prove that FDSKL has a sublinear convergence rate, and can guarantee the data security under the semi-honest assumption. Extensive experimental results on a variety of benchmark datasets show that FDSKL is significantly faster than state-of-the-art federated learning methods when dealing with kernels, while retaining the similar generalization performance.