 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLego: Interactive and Scalable Topic Exploration Through Model Reuse
Aug 11, 2025With massive texts on social media, users and analysts often rely on topic modeling techniques to quickly extract key themes and gain insights. Traditional topic modeling techniques, such as Latent Dirichlet Allocation (LDA), provide valuable insights but are computationally expensive, making them impractical for real-time data analysis. Although recent advances in distributed training and fast sampling methods have improved efficiency, real-time topic exploration remains a significant challenge. In this paper, we present MLego, an interactive query framework designed to support real-time topic modeling analysis by leveraging model materialization and reuse. Instead of retraining models from scratch, MLego efficiently merges materialized topic models to construct approximate results at interactive speeds. To further enhance efficiency, we introduce a hierarchical plan search strategy for single queries and an optimized query reordering technique for batch queries. We integrate MLego into a visual analytics prototype system, enabling users to explore large-scale textual datasets through interactive queries. Extensive experiments demonstrate that MLego significantly reduces computation costs while maintaining high-quality topic modeling results. MLego enhances existing visual analytics approaches, which primarily focus on user-driven topic modeling, by enabling real-time, query-driven exploration. This complements traditional methods and bridges the gap between scalable topic modeling and interactive data analysis.
MAPN: Enhancing Heterogeneous Sparse Graph Representation by Mamba-based Asynchronous Aggregation
Feb 23, 2025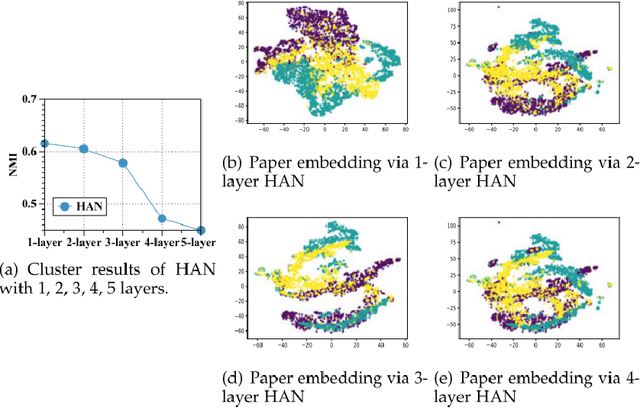
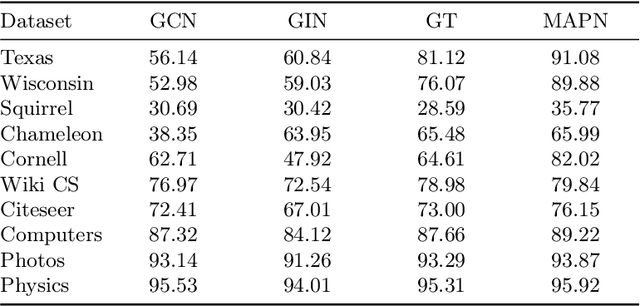
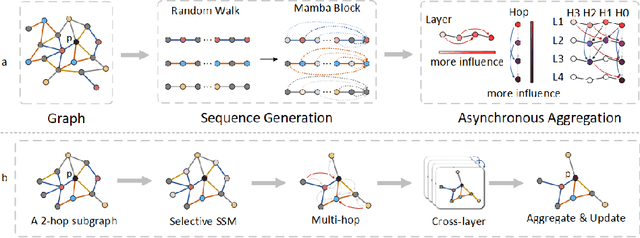
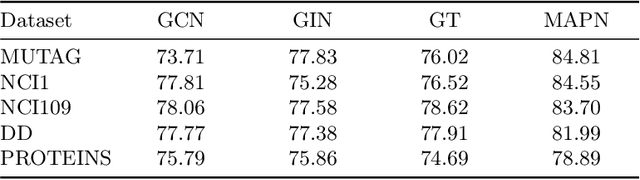
Graph neural networks (GNNs) have become the state of the art for various graph-related tasks and are particularly prominent in heterogeneous graphs (HetGs). However, several issues plague this paradigm: first, the difficulty in fully utilizing long-range information, known as over-squashing; second, the tendency for excessive message-passing layers to produce indistinguishable representations, referred to as over-smoothing; and finally, the inadequacy of conventional MPNNs to train effectively on large sparse graphs. To address these challenges in deep neural networks for large-scale heterogeneous graphs, this paper introduces the Mamba-based Asynchronous Propagation Network (MAPN), which enhances the representation of heterogeneous sparse graphs. MAPN consists of two primary components: node sequence generation and semantic information aggregation. Node sequences are initially generated based on meta-paths through random walks, which serve as the foundation for a spatial state model that extracts essential information from nodes at various distances. It then asynchronously aggregates semantic information across multiple hops and layers, effectively preserving unique node characteristics and mitigating issues related to deep network degradation. Extensive experiments across diverse datasets demonstrate the effectiveness of MAPN in graph embeddings for various downstream tasks underscoring its substantial benefits for graph representation in large sparse heterogeneous graphs.
HetFS: A Method for Fast Similarity Search with Ad-hoc Meta-paths on Heterogeneous Information Networks
Feb 22, 2025Numerous real-world information networks form Heterogeneous Information Networks (HINs) with diverse objects and relations represented as nodes and edges in heterogeneous graphs. Similarity between nodes quantifies how closely two nodes resemble each other, mainly depending on the similarity of the nodes they are connected to, recursively. Users may be interested in only specific types of connections in the similarity definition, represented as meta-paths, i.e., a sequence of node and edge types. Existing Heterogeneous Graph Neural Network (HGNN)-based similarity search methods may accommodate meta-paths, but require retraining for different meta-paths. Conversely, existing path-based similarity search methods may switch flexibly between meta-paths but often suffer from lower accuracy, as they rely solely on path information. This paper proposes HetFS, a Fast Similarity method for ad-hoc queries with user-given meta-paths on Heterogeneous information networks. HetFS provides similarity results based on path information that satisfies the meta-path restriction, as well as node content. Extensive experiments demonstrate the effectiveness and efficiency of HetFS in addressing ad-hoc queries, outperforming state-of-the-art HGNNs and path-based approaches, and showing strong performance in downstream applications, including link prediction, node classification, and clustering.
FHGE: A Fast Heterogeneous Graph Embedding with Ad-hoc Meta-paths
Feb 22, 2025Graph neural networks (GNNs) have emerged as the state of the art for a variety of graph-related tasks and have been widely used in Heterogeneous Graphs (HetGs), where meta-paths help encode specific semantics between various node types. Despite the revolutionary representation capabilities of existing heterogeneous GNNs (HGNNs) due to their focus on improving the effectiveness of heterogeneity capturing, the huge training costs hinder their practical deployment in real-world scenarios that frequently require handling ad-hoc queries with user-defined meta-paths. To address this, we propose FHGE, a Fast Heterogeneous Graph Embedding designed for efficient, retraining-free generation of meta-path-guided graph embeddings. The key design of the proposed framework is two-fold: segmentation and reconstruction modules. It employs Meta-Path Units (MPUs) to segment the graph into local and global components, enabling swift integration of node embeddings from relevant MPUs during reconstruction and allowing quick adaptation to specific meta-paths. In addition, a dual attention mechanism is applied to enhance semantics capturing. Extensive experiments across diverse datasets demonstrate the effectiveness and efficiency of FHGE in generating meta-path-guided graph embeddings and downstream tasks, such as link prediction and node classification, highlighting its significant advantages for real-time graph analysis in ad-hoc queries.
Grounding Natural Language to SQL Translation with Data-Based Self-Explanations
Nov 05, 2024Natural Language Interfaces for Databases empower non-technical users to interact with data using natural language (NL). Advanced approaches, utilizing either neural sequence-to-sequence or more recent sophisticated large-scale language models, typically implement NL to SQL (NL2SQL) translation in an end-to-end fashion. However, like humans, these end-to-end translation models may not always generate the best SQL output on their first try. In this paper, we propose CycleSQL, an iterative framework designed for end-to-end translation models to autonomously generate the best output through self-evaluation. The main idea of CycleSQL is to introduce data-grounded NL explanations of query results as self-provided feedback, and use the feedback to validate the correctness of the translation iteratively, hence improving the overall translation accuracy. Extensive experiments, including quantitative and qualitative evaluations, are conducted to study CycleSQL by applying it to seven existing translation models on five widely used benchmarks. The results show that 1) the feedback loop introduced in CycleSQL can consistently improve the performance of existing models, and in particular, by applying CycleSQL to RESDSQL, obtains a translation accuracy of 82.0% (+2.6%) on the validation set, and 81.6% (+3.2%) on the test set of Spider benchmark; 2) the generated NL explanations can also provide insightful information for users, aiding in the comprehension of translation results and consequently enhancing the interpretability of NL2SQL translation.
RoarGraph: A Projected Bipartite Graph for Efficient Cross-Modal Approximate Nearest Neighbor Search
Aug 16, 2024Approximate Nearest Neighbor Search (ANNS) is a fundamental and critical component in many applications, including recommendation systems and large language model-based applications. With the advancement of multimodal neural models, which transform data from different modalities into a shared high-dimensional space as feature vectors, cross-modal ANNS aims to use the data vector from one modality (e.g., texts) as the query to retrieve the most similar items from another (e.g., images or videos). However, there is an inherent distribution gap between embeddings from different modalities, and cross-modal queries become Out-of-Distribution (OOD) to the base data. Consequently, state-of-the-art ANNS approaches suffer poor performance for OOD workloads. In this paper, we quantitatively analyze the properties of the OOD workloads to gain an understanding of their ANNS efficiency. Unlike single-modal workloads, we reveal OOD queries spatially deviate from base data, and the k-nearest neighbors of an OOD query are distant from each other in the embedding space. The property breaks the assumptions of existing ANNS approaches and mismatches their design for efficient search. With insights from the OOD workloads, we propose pRojected bipartite Graph (RoarGraph), an efficient ANNS graph index built under the guidance of query distribution. Extensive experiments show that RoarGraph significantly outperforms state-of-the-art approaches on modern cross-modal datasets, achieving up to 3.56x faster search speed at a 90% recall rate for OOD queries.
PURPLE: Making a Large Language Model a Better SQL Writer
Mar 29, 2024Large Language Model (LLM) techniques play an increasingly important role in Natural Language to SQL (NL2SQL) translation. LLMs trained by extensive corpora have strong natural language understanding and basic SQL generation abilities without additional tuning specific to NL2SQL tasks. Existing LLMs-based NL2SQL approaches try to improve the translation by enhancing the LLMs with an emphasis on user intention understanding. However, LLMs sometimes fail to generate appropriate SQL due to their lack of knowledge in organizing complex logical operator composition. A promising method is to input the LLMs with demonstrations, which include known NL2SQL translations from various databases. LLMs can learn to organize operator compositions from the input demonstrations for the given task. In this paper, we propose PURPLE (Pre-trained models Utilized to Retrieve Prompts for Logical Enhancement), which improves accuracy by retrieving demonstrations containing the requisite logical operator composition for the NL2SQL task on hand, thereby guiding LLMs to produce better SQL translation. PURPLE achieves a new state-of-the-art performance of 80.5% exact-set match accuracy and 87.8% execution match accuracy on the validation set of the popular NL2SQL benchmark Spider. PURPLE maintains high accuracy across diverse benchmarks, budgetary constraints, and various LLMs, showing robustness and cost-effectiveness.
Metasql: A Generate-then-Rank Framework for Natural Language to SQL Translation
Feb 27, 2024The Natural Language Interface to Databases (NLIDB) empowers non-technical users with database access through intuitive natural language (NL) interactions. Advanced approaches, utilizing neural sequence-to-sequence models or large-scale language models, typically employ auto-regressive decoding to generate unique SQL queries sequentially. While these translation models have greatly improved the overall translation accuracy, surpassing 70% on NLIDB benchmarks, the use of auto-regressive decoding to generate single SQL queries may result in sub-optimal outputs, potentially leading to erroneous translations. In this paper, we propose Metasql, a unified generate-then-rank framework that can be flexibly incorporated with existing NLIDBs to consistently improve their translation accuracy. Metasql introduces query metadata to control the generation of better SQL query candidates and uses learning-to-rank algorithms to retrieve globally optimized queries. Specifically, Metasql first breaks down the meaning of the given NL query into a set of possible query metadata, representing the basic concepts of the semantics. These metadata are then used as language constraints to steer the underlying translation model toward generating a set of candidate SQL queries. Finally, Metasql ranks the candidates to identify the best matching one for the given NL query. Extensive experiments are performed to study Metasql on two public NLIDB benchmarks. The results show that the performance of the translation models can be effectively improved using Metasql.