 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Intrinsic Dimension via Information Bottleneck for Explainable Aspect-based Sentiment Analysis
Feb 28, 2024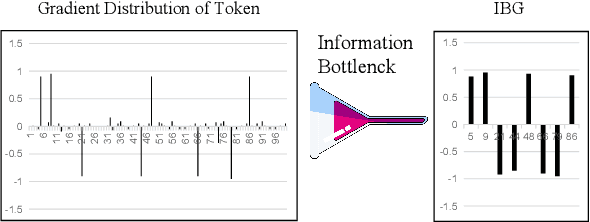
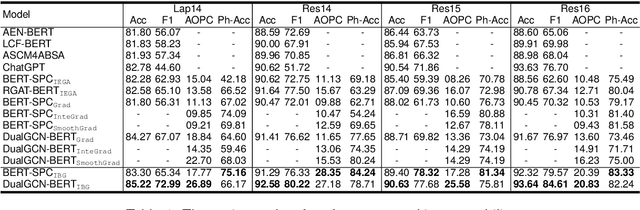
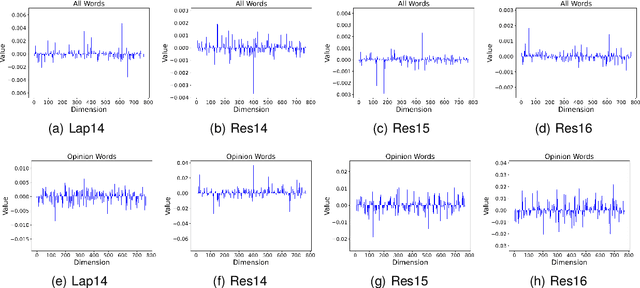

Gradient-based explanation methods are increasingly used to interpret neural models in natural language processing (NLP) due to their high fidelity. Such methods determine word-level importance using dimension-level gradient values through a norm function, often presuming equal significance for all gradient dimensions. However, in the context of Aspect-based Sentiment Analysis (ABSA), our preliminary research suggests that only specific dimensions are pertinent. To address this, we propose the Information Bottleneck-based Gradient (\texttt{IBG}) explanation framework for ABSA. This framework leverages an information bottleneck to refine word embeddings into a concise intrinsic dimension, maintaining essential features and omitting unrelated information. Comprehensive tests show that our \texttt{IBG} approach considerably improves both the models' performance and interpretability by identifying sentiment-aware features.
Tell Model Where to Attend: Improving Interpretability of Aspect-Based Sentiment Classification via Small Explanation Annotations
Feb 21, 2023Gradient-based explanation methods play an important role in the field of interpreting complex deep neural networks for NLP models. However, the existing work has shown that the gradients of a model are unstable and easily manipulable, which impacts the model's reliability largely. According to our preliminary analyses, we also find the interpretability of gradient-based methods is limited for complex tasks, such as aspect-based sentiment classification (ABSC). In this paper, we propose an \textbf{I}nterpretation-\textbf{E}nhanced \textbf{G}radient-based framework for \textbf{A}BSC via a small number of explanation annotations, namely \texttt{{IEGA}}. Particularly, we first calculate the word-level saliency map based on gradients to measure the importance of the words in the sentence towards the given aspect. Then, we design a gradient correction module to enhance the model's attention on the correct parts (e.g., opinion words). Our model is model agnostic and task agnostic so that it can be integrated into the existing ABSC methods or other tasks. Comprehensive experimental results on four benchmark datasets show that our \texttt{IEGA} can improve not only the interpretability of the model but also the performance and robustness.