 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Contrast Consistency of Open-Domain Question Answering Systems on Minimally Edited Questions
May 23, 2023Contrast consistency, the ability of a model to make consistently correct predictions in the presence of perturbations, is an essential aspect in NLP. While studied in tasks such as sentiment analysis and reading comprehension, it remains unexplored in open-domain question answering (OpenQA) due to the difficulty of collecting perturbed questions that satisfy factuality requirements. In this work, we collect minimally edited questions as challenging contrast sets to evaluate OpenQA models. Our collection approach combines both human annotation and large language model generation. We find that the widely used dense passage retriever (DPR) performs poorly on our contrast sets, despite fitting the training set well and performing competitively on standard test sets. To address this issue, we introduce a simple and effective query-side contrastive loss with the aid of data augmentation to improve DPR training. Our experiments on the contrast sets demonstrate that DPR's contrast consistency is improved without sacrificing its accuracy on the standard test sets.
On the Relationship between Counterfactual Explainer and Recommender: A Framework and Preliminary Observations
Jul 09, 2022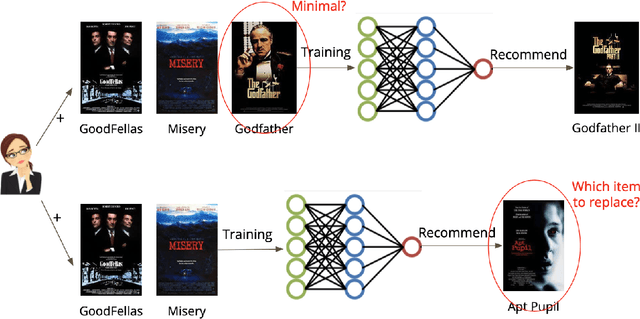

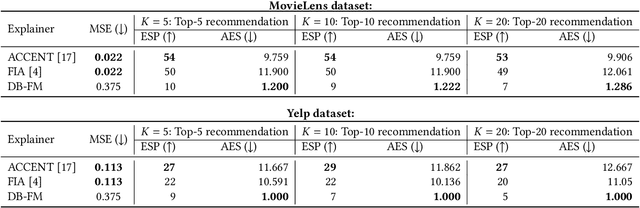
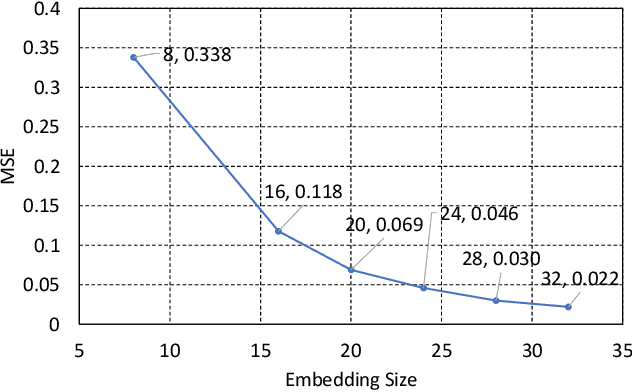
Recommender systems employ machine learning models to learn from historical data to predict the preferences of users. Deep neural network (DNN) models such as neural collaborative filtering (NCF) are increasingly popular. However, the tangibility and trustworthiness of the recommendations are questionable due to the complexity and lack of explainability of the models. To enable explainability, recent techniques such as ACCENT and FIA are looking for counterfactual explanations that are specific historical actions of a user, the removal of which leads to a change to the recommendation result. In this work, we present a general framework for both DNN and non-DNN models so that the counterfactual explainers all belong to it with specific choices of components. This framework first estimates the influence of a certain historical action after its removal and then uses search algorithms to find the minimal set of such actions for the counterfactual explanation. With this framework, we are able to investigate the relationship between the explainers and recommenders. We empirically study two recommender models (NCF and Factorization Machine) and two datasets (MovieLens and Yelp). We analyze the relationship between the performance of the recommender and the quality of the explainer. We observe that with standard evaluation metrics, the explainers deliver worse performance when the recommendations are more accurate. This indicates that having good explanations to correct predictions is harder than having them to wrong predictions. The community needs more fine-grained evaluation metrics to measure the quality of counterfactual explanations to recommender systems.