 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing the confounds of accompaniments in singer identification
Feb 17, 2020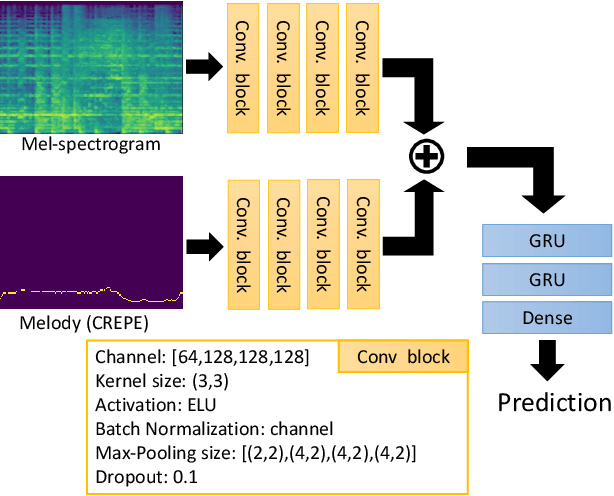


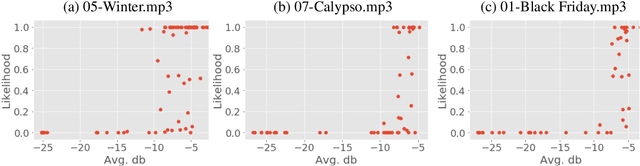
Identifying singers is an important task with many applications. However, the task remains challenging due to many issues. One major issue is related to the confounding factors from the background instrumental music that is mixed with the vocals in music production. A singer identification model may learn to extract non-vocal related features from the instrumental part of the songs, if a singer only sings in certain musical contexts (e.g., genres). The model cannot therefore generalize well when the singer sings in unseen contexts. In this paper, we attempt to address this issue. Specifically, we employ open-unmix, an open source tool with state-of-the-art performance in source separation, to separate the vocal and instrumental tracks of music. We then investigate two means to train a singer identification model: by learning from the separated vocal only, or from an augmented set of data where we "shuffle-and-remix" the separated vocal tracks and instrumental tracks of different songs to artificially make the singers sing in different contexts. We also incorporate melodic features learned from the vocal melody contour for better performance. Evaluation results on a benchmark dataset called the artist20 shows that this data augmentation method greatly improves the accuracy of singer identification.
Backpropagation with N-D Vector-Valued Neurons Using Arbitrary Bilinear Products
May 24, 2018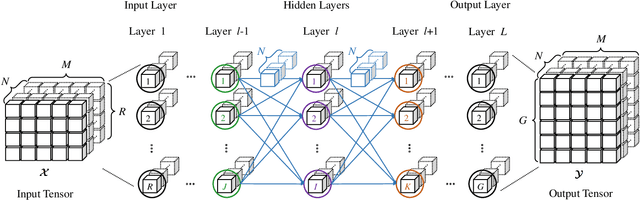
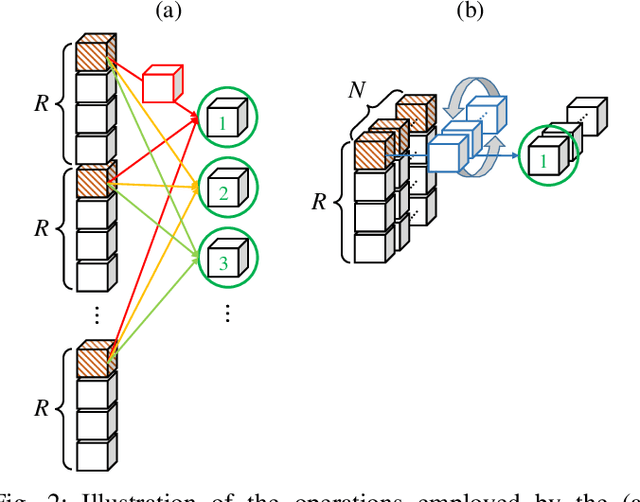
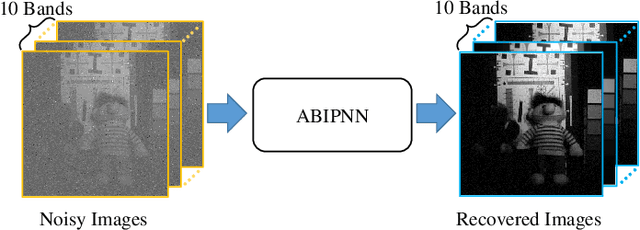

Vector-valued neural learning has emerged as a promising direction in deep learning recently. Traditionally, training data for neural networks (NNs) are formulated as a vector of scalars; however, its performance may not be optimal since associations among adjacent scalars are not modeled. In this paper, we propose a new vector neural architecture called the Arbitrary BIlinear Product Neural Network (ABIPNN), which processes information as vectors in each neuron, and the feedforward projections are defined using arbitrary bilinear products. Such bilinear products can include circular convolution, seven-dimensional vector product, skew circular convolution, reversed- time circular convolution, or other new products not seen in previous work. As a proof-of-concept, we apply our proposed network to multispectral image denoising and singing voice sepa- ration. Experimental results show that ABIPNN gains substantial improvements when compared to conventional NNs, suggesting that associations are learned during training.
SVSGAN: Singing Voice Separation via Generative Adversarial Network
Nov 13, 2017
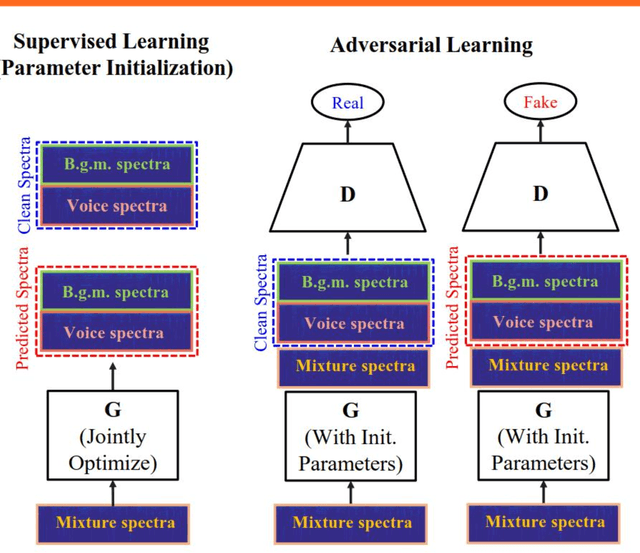
Separating two sources from an audio mixture is an important task with many applications. It is a challenging problem since only one signal channel is available for analysis. In this paper, we propose a novel framework for singing voice separation using the generative adversarial network (GAN) with a time-frequency masking function. The mixture spectra is considered to be a distribution and is mapped to the clean spectra which is also considered a distribtution. The approximation of distributions between mixture spectra and clean spectra is performed during the adversarial training process. In contrast with current deep learning approaches for source separation, the parameters of the proposed framework are first initialized in a supervised setting and then optimized by the training procedure of GAN in an unsupervised setting. Experimental results on three datasets (MIR-1K, iKala and DSD100) show that performance can be improved by the proposed framework consisting of conventional networks.