 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSinging Style Transfer Using Cycle-Consistent Boundary Equilibrium Generative Adversarial Networks
Jul 06, 2018
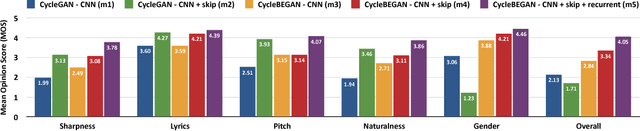
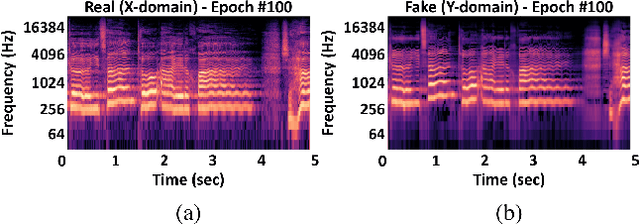
Can we make a famous rap singer like Eminem sing whatever our favorite song? Singing style transfer attempts to make this possible, by replacing the vocal of a song from the source singer to the target singer. This paper presents a method that learns from unpaired data for singing style transfer using generative adversarial networks.
* 3 pages, 3 figures, demo website: http://mirlab.org/users/haley.wu/cybegan
Backpropagation with N-D Vector-Valued Neurons Using Arbitrary Bilinear Products
May 24, 2018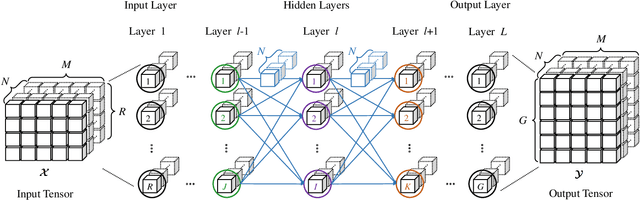
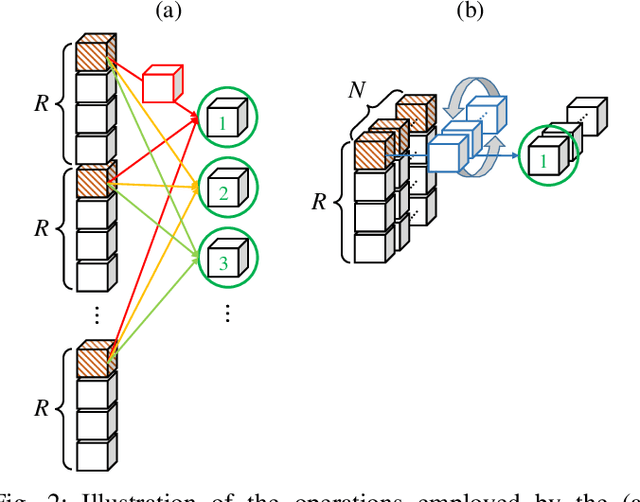
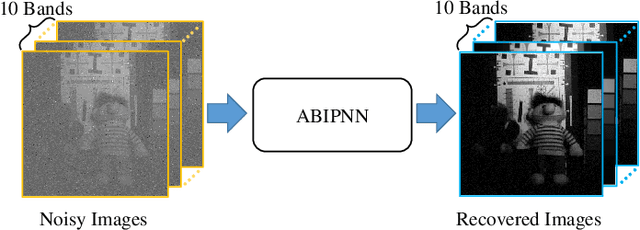

Vector-valued neural learning has emerged as a promising direction in deep learning recently. Traditionally, training data for neural networks (NNs) are formulated as a vector of scalars; however, its performance may not be optimal since associations among adjacent scalars are not modeled. In this paper, we propose a new vector neural architecture called the Arbitrary BIlinear Product Neural Network (ABIPNN), which processes information as vectors in each neuron, and the feedforward projections are defined using arbitrary bilinear products. Such bilinear products can include circular convolution, seven-dimensional vector product, skew circular convolution, reversed- time circular convolution, or other new products not seen in previous work. As a proof-of-concept, we apply our proposed network to multispectral image denoising and singing voice sepa- ration. Experimental results show that ABIPNN gains substantial improvements when compared to conventional NNs, suggesting that associations are learned during training.