 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing the confounds of accompaniments in singer identification
Feb 17, 2020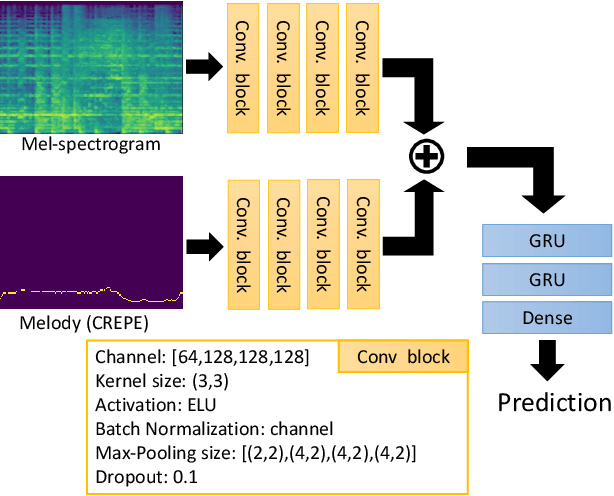


Identifying singers is an important task with many applications. However, the task remains challenging due to many issues. One major issue is related to the confounding factors from the background instrumental music that is mixed with the vocals in music production. A singer identification model may learn to extract non-vocal related features from the instrumental part of the songs, if a singer only sings in certain musical contexts (e.g., genres). The model cannot therefore generalize well when the singer sings in unseen contexts. In this paper, we attempt to address this issue. Specifically, we employ open-unmix, an open source tool with state-of-the-art performance in source separation, to separate the vocal and instrumental tracks of music. We then investigate two means to train a singer identification model: by learning from the separated vocal only, or from an augmented set of data where we "shuffle-and-remix" the separated vocal tracks and instrumental tracks of different songs to artificially make the singers sing in different contexts. We also incorporate melodic features learned from the vocal melody contour for better performance. Evaluation results on a benchmark dataset called the artist20 shows that this data augmentation method greatly improves the accuracy of singer identification.