 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Language Models for Code-related Tasks
Jan 08, 2026Recent advances in language models (LMs) have driven significant progress in various software engineering tasks. However, existing LMs still struggle with complex programming scenarios due to limitations in data quality, model architecture, and reasoning capability. This research systematically addresses these challenges through three complementary directions: (1) improving code data quality with a code difference-guided adversarial augmentation technique (CODA) and a code denoising technique (CodeDenoise); (2) enhancing model architecture via syntax-guided code LMs (LEAM and LEAM++); and (3) advancing model reasoning with a prompting technique (muFiX) and an agent-based technique (Specine). These techniques aim to promote the practical adoption of LMs in software development and further advance intelligent software engineering.
Distilling Desired Comments for Enhanced Code Review with Large Language Models
Dec 29, 2024There has been a growing interest in using Large Language Models (LLMs) for code review thanks to their proven proficiency in code comprehension. The primary objective of most review scenarios is to generate desired review comments (DRCs) that explicitly identify issues to trigger code fixes. However, existing LLM-based solutions are not so effective in generating DRCs for various reasons such as hallucination. To enhance their code review ability, they need to be fine-tuned with a customized dataset that is ideally full of DRCs. Nevertheless, such a dataset is not yet available, while manual annotation of DRCs is too laborious to be practical. In this paper, we propose a dataset distillation method, Desiview, which can automatically construct a distilled dataset by identifying DRCs from a code review dataset. Experiments on the CodeReviewer dataset comprising more than 150K review entries show that Desiview achieves an impressive performance of 88.93%, 80.37%, 86.67%, and 84.44% in terms of Precision, Recall, Accuracy, and F1, respectively, surpassing state-of-the-art methods. To validate the effect of such a distilled dataset on enhancing LLMs' code review ability, we first fine-tune the latest LLaMA series (i.e., LLaMA 3 and LLaMA 3.1) to build model Desiview4FT. We then enhance the model training effect through KTO alignment by feeding those review comments identified as non-DRCs to the LLMs, resulting in model Desiview4FA. Verification results indicate that Desiview4FA slightly outperforms Desiview4FT, while both models have significantly improved against the base models in terms of generating DRCs. Human evaluation confirms that both models identify issues more accurately and tend to generate review comments that better describe the issues contained in the code than the base LLMs do.
Enhanced Fairness Testing via Generating Effective Initial Individual Discriminatory Instances
Sep 17, 2022

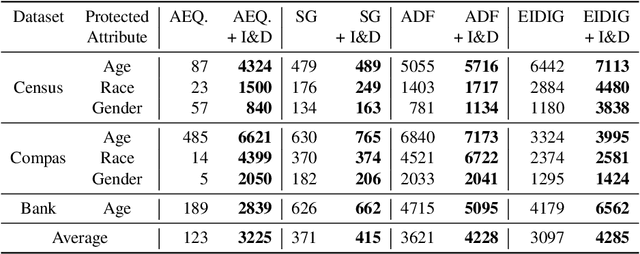

Fairness testing aims at mitigating unintended discrimination in the decision-making process of data-driven AI systems. Individual discrimination may occur when an AI model makes different decisions for two distinct individuals who are distinguishable solely according to protected attributes, such as age and race. Such instances reveal biased AI behaviour, and are called Individual Discriminatory Instances (IDIs). In this paper, we propose an approach for the selection of the initial seeds to generate IDIs for fairness testing. Previous studies mainly used random initial seeds to this end. However this phase is crucial, as these seeds are the basis of the follow-up IDIs generation. We dubbed our proposed seed selection approach I&D. It generates a large number of initial IDIs exhibiting a great diversity, aiming at improving the overall performance of fairness testing. Our empirical study reveal that I&D is able to produce a larger number of IDIs with respect to four state-of-the-art seed generation approaches, generating 1.68X more IDIs on average. Moreover, we compare the use of I&D to train machine learning models and find that using I&D reduces the number of remaining IDIs by 29% when compared to the state-of-the-art, thus indicating that I&D is effective for improving model fairness