 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Fairness Testing via Generating Effective Initial Individual Discriminatory Instances
Paper and Code


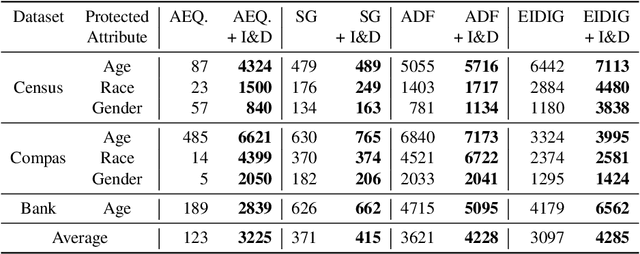

Fairness testing aims at mitigating unintended discrimination in the decision-making process of data-driven AI systems. Individual discrimination may occur when an AI model makes different decisions for two distinct individuals who are distinguishable solely according to protected attributes, such as age and race. Such instances reveal biased AI behaviour, and are called Individual Discriminatory Instances (IDIs). In this paper, we propose an approach for the selection of the initial seeds to generate IDIs for fairness testing. Previous studies mainly used random initial seeds to this end. However this phase is crucial, as these seeds are the basis of the follow-up IDIs generation. We dubbed our proposed seed selection approach I&D. It generates a large number of initial IDIs exhibiting a great diversity, aiming at improving the overall performance of fairness testing. Our empirical study reveal that I&D is able to produce a larger number of IDIs with respect to four state-of-the-art seed generation approaches, generating 1.68X more IDIs on average. Moreover, we compare the use of I&D to train machine learning models and find that using I&D reduces the number of remaining IDIs by 29% when compared to the state-of-the-art, thus indicating that I&D is effective for improving model fairness