 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multimodal Vision-Language Models Generating Non-Generic Text
Jul 09, 2022
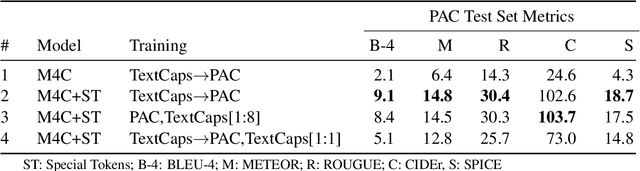
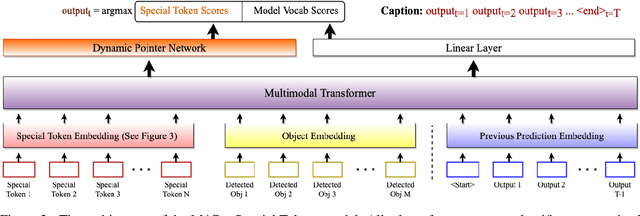

Vision-language models can assess visual context in an image and generate descriptive text. While the generated text may be accurate and syntactically correct, it is often overly general. To address this, recent work has used optical character recognition to supplement visual information with text extracted from an image. In this work, we contend that vision-language models can benefit from additional information that can be extracted from an image, but are not used by current models. We modify previous multimodal frameworks to accept relevant information from any number of auxiliary classifiers. In particular, we focus on person names as an additional set of tokens and create a novel image-caption dataset to facilitate captioning with person names. The dataset, Politicians and Athletes in Captions (PAC), consists of captioned images of well-known people in context. By fine-tuning pretrained models with this dataset, we demonstrate a model that can naturally integrate facial recognition tokens into generated text by training on limited data. For the PAC dataset, we provide a discussion on collection and baseline benchmark scores.
ZoDIAC: Zoneout Dropout Injection Attention Calculation
Jun 28, 2022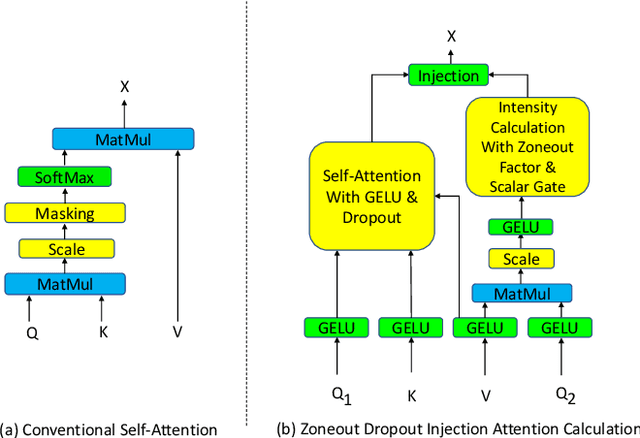
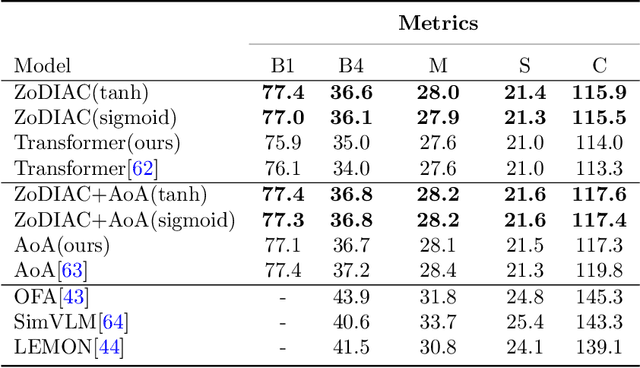
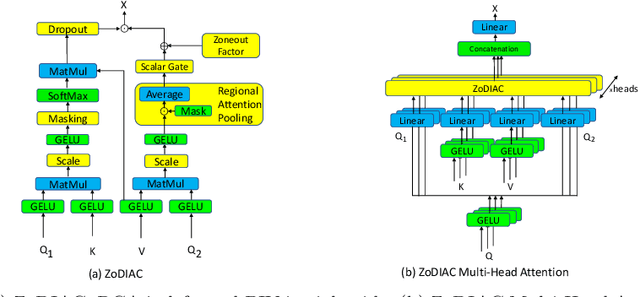
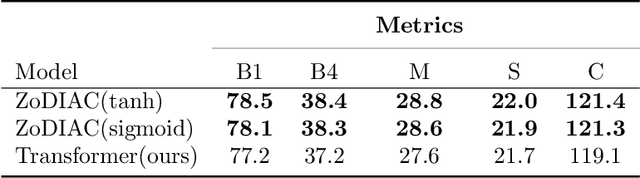
Recently the use of self-attention has yielded to state-of-the-art results in vision-language tasks such as image captioning as well as natural language understanding and generation (NLU and NLG) tasks and computer vision tasks such as image classification. This is since self-attention maps the internal interactions among the elements of input source and target sequences. Although self-attention successfully calculates the attention values and maps the relationships among the elements of input source and target sequence, yet there is no mechanism to control the intensity of attention. In real world, when communicating with each other face to face or vocally, we tend to express different visual and linguistic context with various amounts of intensity. Some words might carry (be spoken with) more stress and weight indicating the importance of that word in the context of the whole sentence. Based on this intuition, we propose Zoneout Dropout Injection Attention Calculation (ZoDIAC) in which the intensities of attention values in the elements of the input sequence are calculated with respect to the context of the elements of input sequence. The results of our experiments reveal that employing ZoDIAC leads to better performance in comparison with the self-attention module in the Transformer model. The ultimate goal is to find out if we could modify self-attention module in the Transformer model with a method that is potentially extensible to other models that leverage on self-attention at their core. Our findings suggest that this particular goal deserves further attention and investigation by the research community. The code for ZoDIAC is available on www.github.com/zanyarz/zodiac .
Neural Attention for Image Captioning: Review of Outstanding Methods
Nov 29, 2021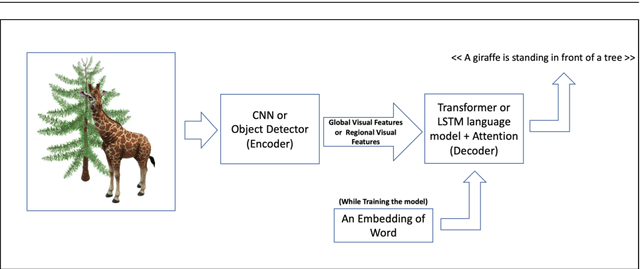

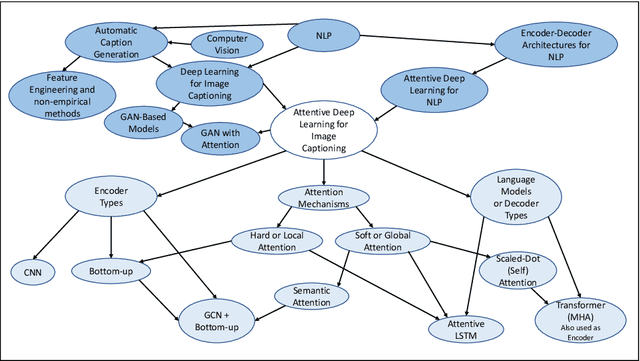
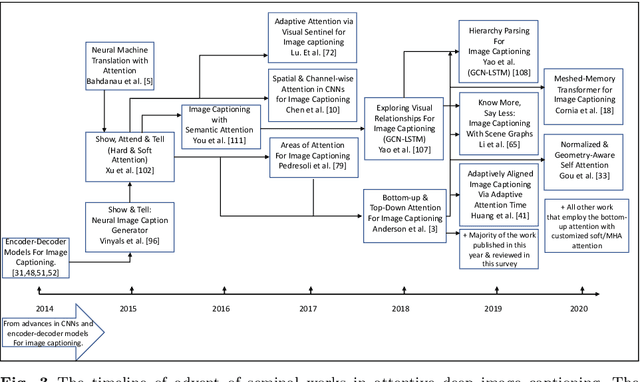
Image captioning is the task of automatically generating sentences that describe an input image in the best way possible. The most successful techniques for automatically generating image captions have recently used attentive deep learning models. There are variations in the way deep learning models with attention are designed. In this survey, we provide a review of literature related to attentive deep learning models for image captioning. Instead of offering a comprehensive review of all prior work on deep image captioning models, we explain various types of attention mechanisms used for the task of image captioning in deep learning models. The most successful deep learning models used for image captioning follow the encoder-decoder architecture, although there are differences in the way these models employ attention mechanisms. Via analysis on performance results from different attentive deep models for image captioning, we aim at finding the most successful types of attention mechanisms in deep models for image captioning. Soft attention, bottom-up attention, and multi-head attention are the types of attention mechanism widely used in state-of-the-art attentive deep learning models for image captioning. At the current time, the best results are achieved from variants of multi-head attention with bottom-up attention.
Neural Twins Talk & Alternative Calculations
Aug 05, 2021
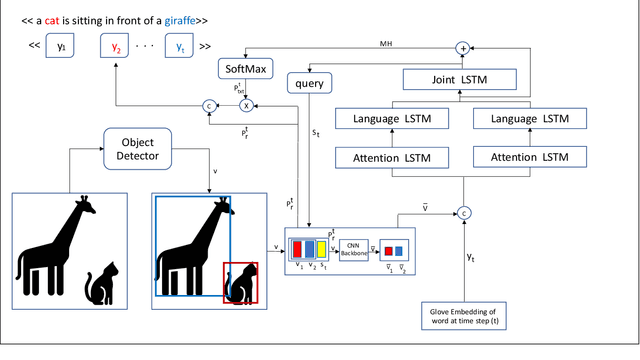
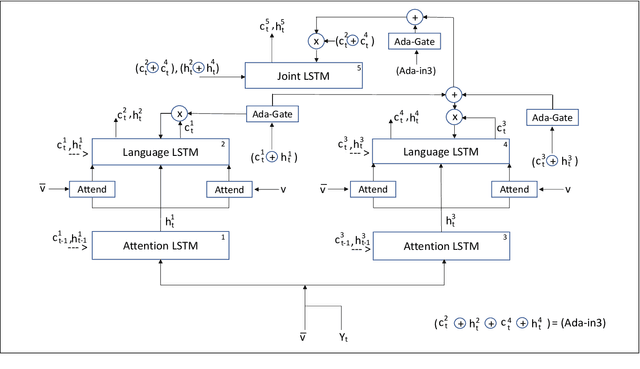

Inspired by how the human brain employs a higher number of neural pathways when describing a highly focused subject, we show that deep attentive models used for the main vision-language task of image captioning, could be extended to achieve better performance. Image captioning bridges a gap between computer vision and natural language processing. Automated image captioning is used as a tool to eliminate the need for human agent for creating descriptive captions for unseen images.Automated image captioning is challenging and yet interesting. One reason is that AI based systems capable of generating sentences that describe an input image could be used in a wide variety of tasks beyond generating captions for unseen images found on web or uploaded to social media. For example, in biology and medical sciences, these systems could provide researchers and physicians with a brief linguistic description of relevant images, potentially expediting their work.
* This paper was published at World Scientific Journal, International Journal of Semantic Computing. This is a preprint version that was submitted to the journal before final publication
Neural Twins Talk
Sep 26, 2020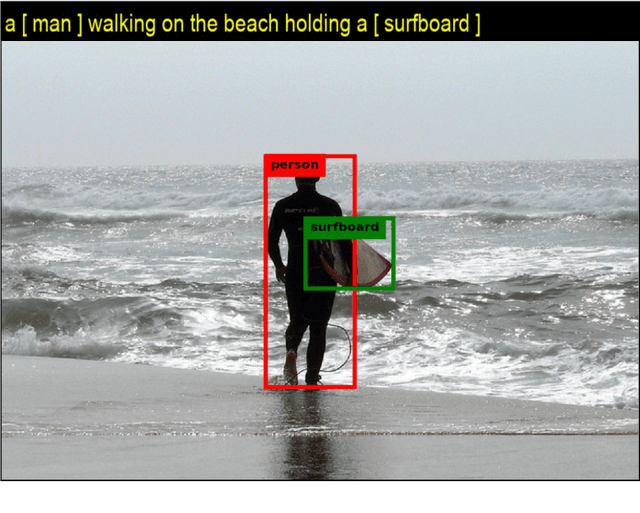
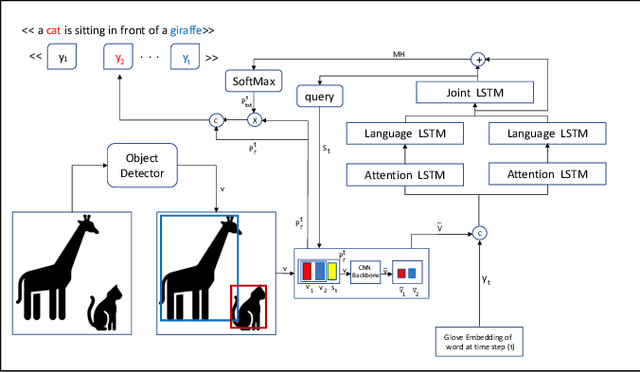
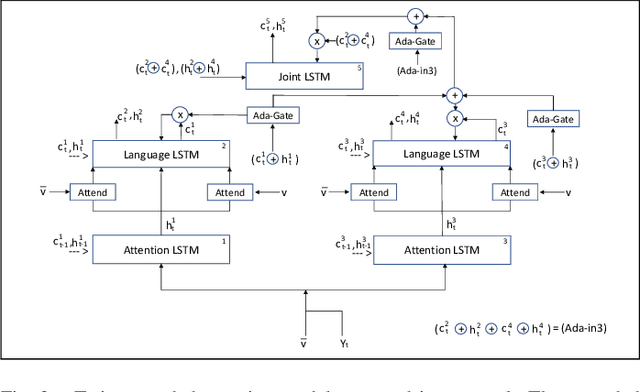

Inspired by how the human brain employs more neural pathways when increasing the focus on a subject, we introduce a novel twin cascaded attention model that outperforms a state-of-the-art image captioning model that was originally implemented using one channel of attention for the visual grounding task. Visual grounding ensures the existence of words in the caption sentence that are grounded into a particular region in the input image. After a deep learning model is trained on visual grounding task, the model employs the learned patterns regarding the visual grounding and the order of objects in the caption sentences, when generating captions. We report the results of our experiments in three image captioning tasks on the COCO dataset. The results are reported using standard image captioning metrics to show the improvements achieved by our model over the previous image captioning model. The results gathered from our experiments suggest that employing more parallel attention pathways in a deep neural network leads to higher performance. Our implementation of NTT is publicly available at: https://github.com/zanyarz/NeuralTwinsTalk.
* Copyright 2020 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works