 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Twins Talk
Paper and Code
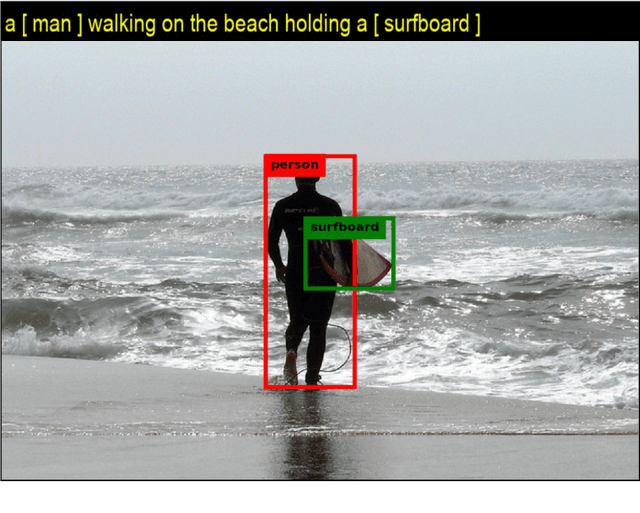
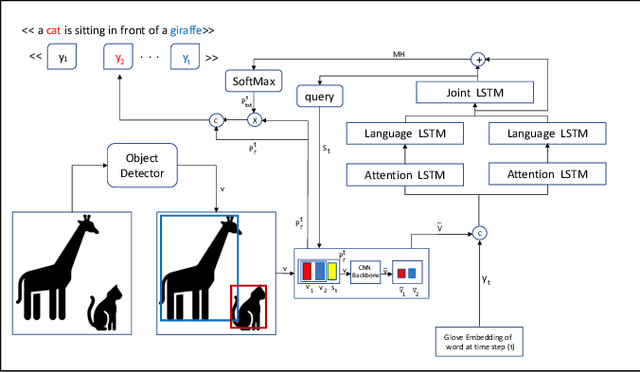
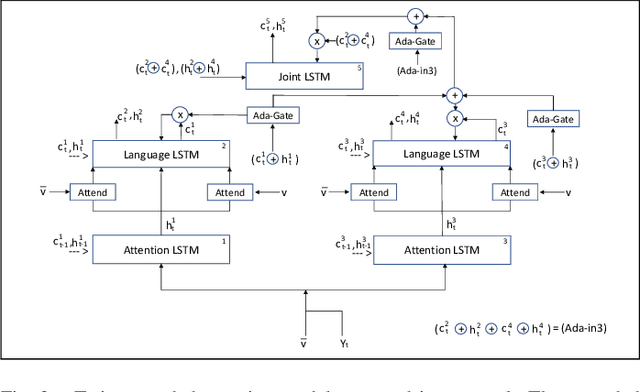

Inspired by how the human brain employs more neural pathways when increasing the focus on a subject, we introduce a novel twin cascaded attention model that outperforms a state-of-the-art image captioning model that was originally implemented using one channel of attention for the visual grounding task. Visual grounding ensures the existence of words in the caption sentence that are grounded into a particular region in the input image. After a deep learning model is trained on visual grounding task, the model employs the learned patterns regarding the visual grounding and the order of objects in the caption sentences, when generating captions. We report the results of our experiments in three image captioning tasks on the COCO dataset. The results are reported using standard image captioning metrics to show the improvements achieved by our model over the previous image captioning model. The results gathered from our experiments suggest that employing more parallel attention pathways in a deep neural network leads to higher performance. Our implementation of NTT is publicly available at: https://github.com/zanyarz/NeuralTwinsTalk.