 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multimodal Vision-Language Models Generating Non-Generic Text
Paper and Code
Jul 09, 2022
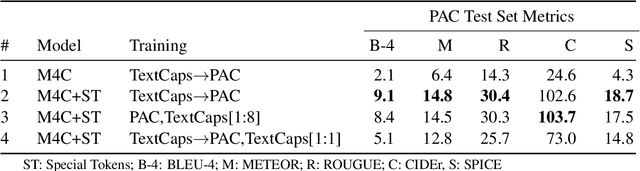
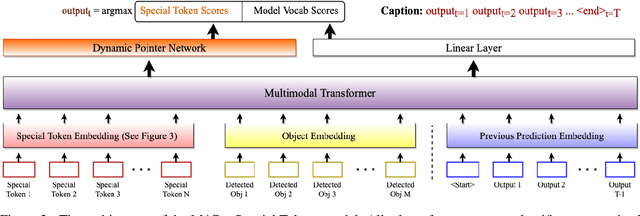

Vision-language models can assess visual context in an image and generate descriptive text. While the generated text may be accurate and syntactically correct, it is often overly general. To address this, recent work has used optical character recognition to supplement visual information with text extracted from an image. In this work, we contend that vision-language models can benefit from additional information that can be extracted from an image, but are not used by current models. We modify previous multimodal frameworks to accept relevant information from any number of auxiliary classifiers. In particular, we focus on person names as an additional set of tokens and create a novel image-caption dataset to facilitate captioning with person names. The dataset, Politicians and Athletes in Captions (PAC), consists of captioned images of well-known people in context. By fine-tuning pretrained models with this dataset, we demonstrate a model that can naturally integrate facial recognition tokens into generated text by training on limited data. For the PAC dataset, we provide a discussion on collection and baseline benchmark scores.